
About Chutes
Chutes.ai is a decentralized serverless AI compute platform built on Bittensor Subnet 64, enabling developers to deploy, run, and scale AI models without managing infrastructure. The platform processes nearly 160 billion tokens daily serving over 400,000 users with up to 90% lower costs than traditional providers through a distributed network of GPU miners compensated with TAO tokens. Key features include always-hot serverless compute with instant inference, model-agnostic support for LLMs, image, and audio models plus custom code, fully abstracted infrastructure handling provisioning and scaling automatically, standardized API access with OpenRouter integration, and open pay-per-use pricing. The roadmap includes long-running jobs, fine-tuning capabilities, AI agents, and Trusted Execution Environments for enhanced privacy, with a startup accelerator offering up to $20,000 in credits.
Step by step guide to use Chutes API Key to chat with AI
1. Get Your Chutes API Key
First, you'll need to obtain an API key from Chutes. This key allows you to access their AI models directly and pay only for what you use.
- Visit Chutes's API console
- Sign up or log in to your account
- Navigate to the API keys section
- Generate a new API key (copy it immediately as some providers only show it once)
- Save your API key in a secure password manager or encrypted note
2. Connect Your Chutes API Key on TypingMind
Once you have your Chutes API key, connecting it to TypingMind to chat with AI is straightforward:
- Open TypingMind in your browser
- Click the "Settings" icon (gear symbol)
- Navigate to "Models" section
- Click "Add Custom Model"
- Fill in the model information:Name:
deepseek-ai/DeepSeek-R1 via Chutes(or your preferred name)Endpoint:https://llm.chutes.ai/v1/chat/completionsModel ID:deepseek-ai/DeepSeek-R1for example (check Chutes model list)Context Length: Enter the model's context window (e.g., 32000 for deepseek-ai/DeepSeek-R1)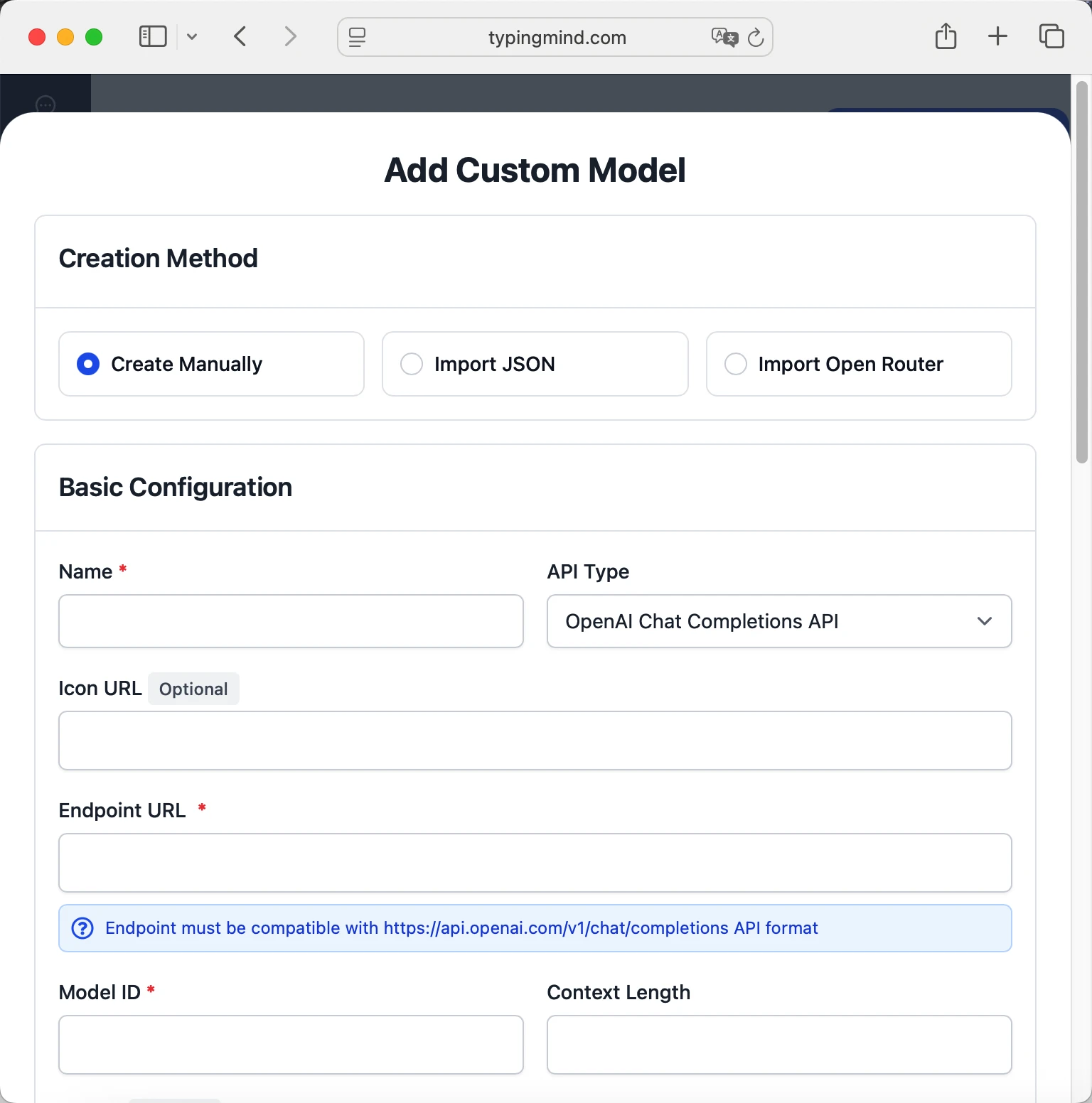 deepseek-ai/DeepSeek-R1https://llm.chutes.ai/v1/chat/completionsdeepseek-ai/DeepSeek-R1 via Chuteshttps://www.typingmind.com/model-logo.webp32000
deepseek-ai/DeepSeek-R1https://llm.chutes.ai/v1/chat/completionsdeepseek-ai/DeepSeek-R1 via Chuteshttps://www.typingmind.com/model-logo.webp32000 - Add custom headers by clicking "Add Custom Headers" in the Advanced Settings section:Authorization:
Bearer <CHUTES_API_KEY>:X-Title:typingmind.comHTTP-Referer:https://www.typingmind.com - Enable "Support Plugins (via OpenAI Functions)" if the model supports the "functions" or "tool_calls" parameter, or enable "Support OpenAI Vision" if the model supports vision.
- Click "Test" to verify the configuration
- If you see "Nice, the endpoint is working!", click "Add Model"
3. Start Chatting with Chutes models
Now you can start chatting with Chutes models through TypingMind:
- Select your preferred Chutes model from the model dropdown menu
- Start typing your message in the chat input
- Enjoy faster responses and better features than the official interface
- Switch between different AI models as needed
- Use specific, detailed prompts for better responses (How to use Prompt Library)
- Create AI agents with custom instructions for repeated tasks (How to create AI Agents)
- Use plugins to extend Chutes capabilities (How to use plugins)
- Upload documents and images directly to chat for AI analysis and discussion (Chat with documents)
4. Monitor Your AI Usage and Costs
One of the biggest advantages of using API keys with TypingMind is cost transparency and control. Unlike fixed subscriptions, you pay only for what you actually use. Visit https://chutes.ai/app/api/logs to monitor your Chutes API usage and set spending limits.
- Use less expensive models for simple tasks
- Keep prompts concise but specific to reduce token usage
- Use TypingMind's prompt caching to reduce repeat costs (How to enable prompt caching)
- Using RAG (retrieval-augmented generation) for large documents to reduce repeat costs (How to use RAG)

Access AionLabs: Aion-2.0 via OpenRouter
Aion-2.0 is a variant of DeepSeek V3.2 optimized for immersive roleplaying and storytelling. It is particularly strong at introducing tension, crises, and conflict into stories, making narratives feel more engaging....

Access Google: Gemini 3.1 Pro Preview via OpenRouter
Gemini 3.1 Pro Preview is Google’s frontier reasoning model, delivering enhanced software engineering performance, improved agentic reliability, and more efficient token usage across complex workflows. Building on the multimodal foundation...

Access Anthropic: Claude Sonnet 4.6 via OpenRouter
Sonnet 4.6 is Anthropic's most capable Sonnet-class model yet, with frontier performance across coding, agents, and professional work. It excels at iterative development, complex codebase navigation, end-to-end project management with...

Access Qwen: Qwen3.5 Plus 2026-02-15 via OpenRouter
The Qwen3.5 native vision-language series Plus models are built on a hybrid architecture that integrates linear attention mechanisms with sparse mixture-of-experts models, achieving higher inference efficiency. In a variety of...

Access Qwen: Qwen3.5 397B A17B via OpenRouter
The Qwen3.5 series 397B-A17B native vision-language model is built on a hybrid architecture that integrates a linear attention mechanism with a sparse mixture-of-experts model, achieving higher inference efficiency. It delivers...

Access MiniMax: MiniMax M2.5 via OpenRouter
MiniMax-M2.5 is a SOTA large language model designed for real-world productivity. Trained in a diverse range of complex real-world digital working environments, M2.5 builds upon the coding expertise of M2.1...

Access Z.ai: GLM 5 via OpenRouter
GLM-5 is Z.ai’s flagship open-source foundation model engineered for complex systems design and long-horizon agent workflows. Built for expert developers, it delivers production-grade performance on large-scale programming tasks, rivaling leading...

Access Qwen: Qwen3 Max Thinking via OpenRouter
Qwen3-Max-Thinking is the flagship reasoning model in the Qwen3 series, designed for high-stakes cognitive tasks that require deep, multi-step reasoning. By significantly scaling model capacity and reinforcement learning compute, it...

Access Anthropic: Claude Opus 4.6 via OpenRouter
Opus 4.6 is Anthropic’s strongest model for coding and long-running professional tasks. It is built for agents that operate across entire workflows rather than single prompts, making it especially effective...

Access Qwen: Qwen3 Coder Next via OpenRouter
Qwen3-Coder-Next is an open-weight causal language model optimized for coding agents and local development workflows. It uses a sparse MoE design with 80B total parameters and only 3B activated per...
Access Free Models Router via OpenRouter
The simplest way to get free inference. openrouter/free is a router that selects free models at random from the models available on OpenRouter. The router smartly filters for models that...

Access StepFun: Step 3.5 Flash (free) via OpenRouter
Step 3.5 Flash is StepFun's most capable open-source foundation model. Built on a sparse Mixture of Experts (MoE) architecture, it selectively activates only 11B of its 196B parameters per token....
