
About Claude (Anthropic)
Claude is a next-generation AI assistant developed by Anthropic, featuring a family of state-of-the-art large language models trained to be safe, accurate, and helpful. The latest models include Claude Sonnet 4.5 (the world's best coding model with advanced agentic capabilities) and Claude Opus 4.1, both offering hybrid reasoning modes, 200K token context windows, and sophisticated vision capabilities.
Key features include tool use for external API integration, code execution environments, multi-step workflow automation, files API, persistent memory management, and enterprise-grade security with deployment on AWS Bedrock and Google Cloud Vertex AI.
Claude excels at complex reasoning, code generation, visual data interpretation, customer support, and building autonomous AI agents with natural, human-like conversations.
Step by step guide to use Anthropic API Key to chat with AI
1. Get Your Anthropic API Key
First, you'll need to obtain an API key from Anthropic. This key allows you to access their AI models directly and pay only for what you use.
- Visit Anthropic's API console
- Sign up or log in to your account
- Navigate to the API keys section
- Generate a new API key (copy it immediately as some providers only show it once)
- Save your API key in a secure password manager or encrypted note
2. Connect Your Anthropic API Key on TypingMind
Once you have your Anthropic API key, connecting it to TypingMind to chat with AI is straightforward:
- Open TypingMind in your browser
- Click the "Settings" icon (gear symbol)
- Navigate to "Models" section
- Click "Add Custom Model"
- Fill in the model information:Name:
claude-opus-4.1 via Anthropic(or your preferred name)Endpoint:https://api.anthropic.com/v1/messagesModel ID:claude-opus-4.1Context Length: Enter the model's context window (e.g., 32000 for claude-opus-4.1)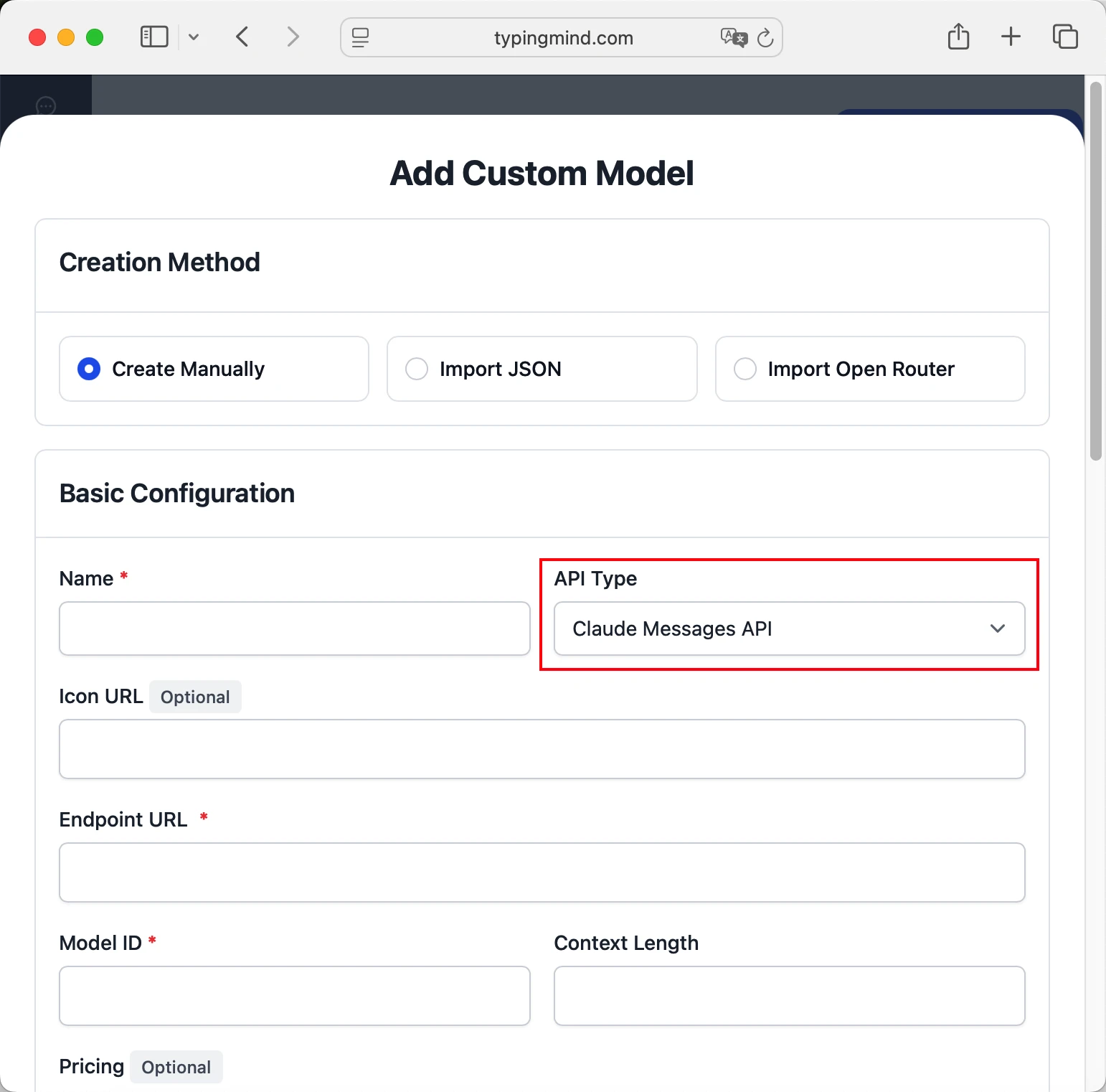 claude-opus-4.1https://api.anthropic.com/v1/messagesclaude-opus-4.1 via Anthropichttps://www.typingmind.com/model-logo.webp32000
claude-opus-4.1https://api.anthropic.com/v1/messagesclaude-opus-4.1 via Anthropichttps://www.typingmind.com/model-logo.webp32000 - Add custom headers by clicking "Add Custom Headers" in the Advanced Settings section:x-api-key:
<CLAUDE_API_KEY>:X-Title:typingmind.comHTTP-Referer:https://www.typingmind.com - Enable "Support Plugins (via OpenAI Functions)" if the model supports the "functions" or "tool_calls" parameter, or enable "Support OpenAI Vision" if the model supports vision.
- Click "Test" to verify the configuration
- If you see "Nice, the endpoint is working!", click "Add Model"
3. Start Chatting with Anthropic models
Now you can start chatting with Claude (Anthropic) models through TypingMind:
- Select your preferred Anthropic model from the model dropdown menu
- Start typing your message in the chat input
- Enjoy faster responses and better features than the official interface
- Switch between different AI models as needed
- Use specific, detailed prompts for better responses (How to use Prompt Library)
- Create AI agents with custom instructions for repeated tasks (How to create AI Agents)
- Use plugins to extend Anthropic capabilities (How to use plugins)
- Upload documents and images directly to chat for AI analysis and discussion (Chat with documents)
4. Monitor Your AI Usage and Costs
One of the biggest advantages of using API keys with TypingMind is cost transparency and control. Unlike fixed subscriptions, you pay only for what you actually use. Visit https://console.anthropic.com/usage to monitor your Anthropic API usage and set spending limits.
| Feature | Anthropic Subscription Plans | Using Anthropic API Keys |
|---|---|---|
| Cost Structure | ❌ Fixed monthly fee Pay even if you don't use it Claude Pro:$20/month (or $17/month annually) | ✅ Pay only for actual usage $0 when you don't use it |
| Usage Limits | ❌ Hard daily/hourly caps You have to wait for the next period to use it again | ✅ Unlimited usage No limits. Only limited by your budget |
| Model Access | ❌ Platform decides available models Old models get discontinued | ✅ Access to all API models Including older & specialized versions |
- Use less expensive models for simple tasks
- Keep prompts concise but specific to reduce token usage
- Use TypingMind's prompt caching to reduce repeat costs (How to enable prompt caching)
- Using RAG (retrieval-augmented generation) for large documents to reduce repeat costs (How to use RAG)

Access Goliath 120B via OpenRouter
A large LLM created by combining two fine-tuned Llama 70B models into one 120B model. Combines Xwin and Euryale. Credits to - [@chargoddard](https://huggingface.co/chargoddard) for developing the framework used to merge...

Access Auto Router via OpenRouter
Your prompt will be processed by a meta-model and routed to one of dozens of models (see below), optimizing for the best possible output. To see which model was used,...

Access OpenAI: GPT-4 Turbo (older v1106) via OpenRouter
The latest GPT-4 Turbo model with vision capabilities. Vision requests can now use JSON mode and function calling. Training data: up to April 2023.

Access OpenAI: GPT-3.5 Turbo Instruct via OpenRouter
This model is a variant of GPT-3.5 Turbo tuned for instructional prompts and omitting chat-related optimizations. Training data: up to Sep 2021.

Access Mistral: Mistral 7B Instruct v0.1 via OpenRouter
A 7.3B parameter model that outperforms Llama 2 13B on all benchmarks, with optimizations for speed and context length.

Access OpenAI: GPT-3.5 Turbo 16k via OpenRouter
This model offers four times the context length of gpt-3.5-turbo, allowing it to support approximately 20 pages of text in a single request at a higher cost. Training data: up...

Access Mancer: Weaver (alpha) via OpenRouter
An attempt to recreate Claude-style verbosity, but don't expect the same level of coherence or memory. Meant for use in roleplay/narrative situations.
Access ReMM SLERP 13B via OpenRouter
A recreation trial of the original MythoMax-L2-B13 but with updated models. #merge

Access MythoMax 13B via OpenRouter
One of the highest performing and most popular fine-tunes of Llama 2 13B, with rich descriptions and roleplay. #merge

Access OpenAI: GPT-4 (older v0314) via OpenRouter
GPT-4-0314 is the first version of GPT-4 released, with a context length of 8,192 tokens, and was supported until June 14. Training data: up to Sep 2021.

Access OpenAI: GPT-4 via OpenRouter
OpenAI's flagship model, GPT-4 is a large-scale multimodal language model capable of solving difficult problems with greater accuracy than previous models due to its broader general knowledge and advanced reasoning...
Access OpenAI: GPT-3.5 Turbo via OpenRouter
GPT-3.5 Turbo is OpenAI's fastest model. It can understand and generate natural language or code, and is optimized for chat and traditional completion tasks. Training data up to Sep 2021.
