
About Jina AI
Jina AI is a specialized AI platform providing best-in-class search infrastructure through embeddings, rerankers, web readers, and small language models for multilingual and multimodal data.
Key offerings include jina-embeddings-v3 (570M parameter model supporting 89 languages with 8K token context and task-specific LoRA adapters for retrieval, clustering, and classification), jina-embeddings-v4 (3.8B parameter multimodal model unifying text and images), Reader API (converts any URL to LLM-ready Markdown using ReaderLM-v2), Reranker API (improves search result accuracy), and DeepSearch (comprehensive search agent combining web search, reading, and reasoning with OpenAI-compatible API).
The platform features FlashAttention 2 optimization, 1024-dimensional embeddings, late-chunking for better snippet selection, and integration with popular frameworks, making it ideal for RAG systems and semantic search applications.
Step by step guide to use Jina AI API Key to chat with AI
1. Get Your Jina AI API Key
First, you'll need to obtain an API key from Jina AI. This key allows you to access their AI models directly and pay only for what you use.
- Visit Jina AI's API console
- Sign up or log in to your account
- Navigate to the API keys section
- Generate a new API key (copy it immediately as some providers only show it once)
- Save your API key in a secure password manager or encrypted note
2. Connect Your Jina AI API Key on TypingMind
Once you have your Jina AI API key, connecting it to TypingMind to chat with AI is straightforward:
- Open TypingMind in your browser
- Click the "Settings" icon (gear symbol)
- Navigate to "Models" section
- Click "Add Custom Model"
- Fill in the model information:Name:
jina-deepsearch-v1 via Jina AI(or your preferred name)Endpoint:https://deepsearch.jina.ai/v1/chat/completionsModel ID:jina-deepsearch-v1for example (check Jina AI model list)Context Length: Enter the model's context window (e.g., 32000 for jina-deepsearch-v1)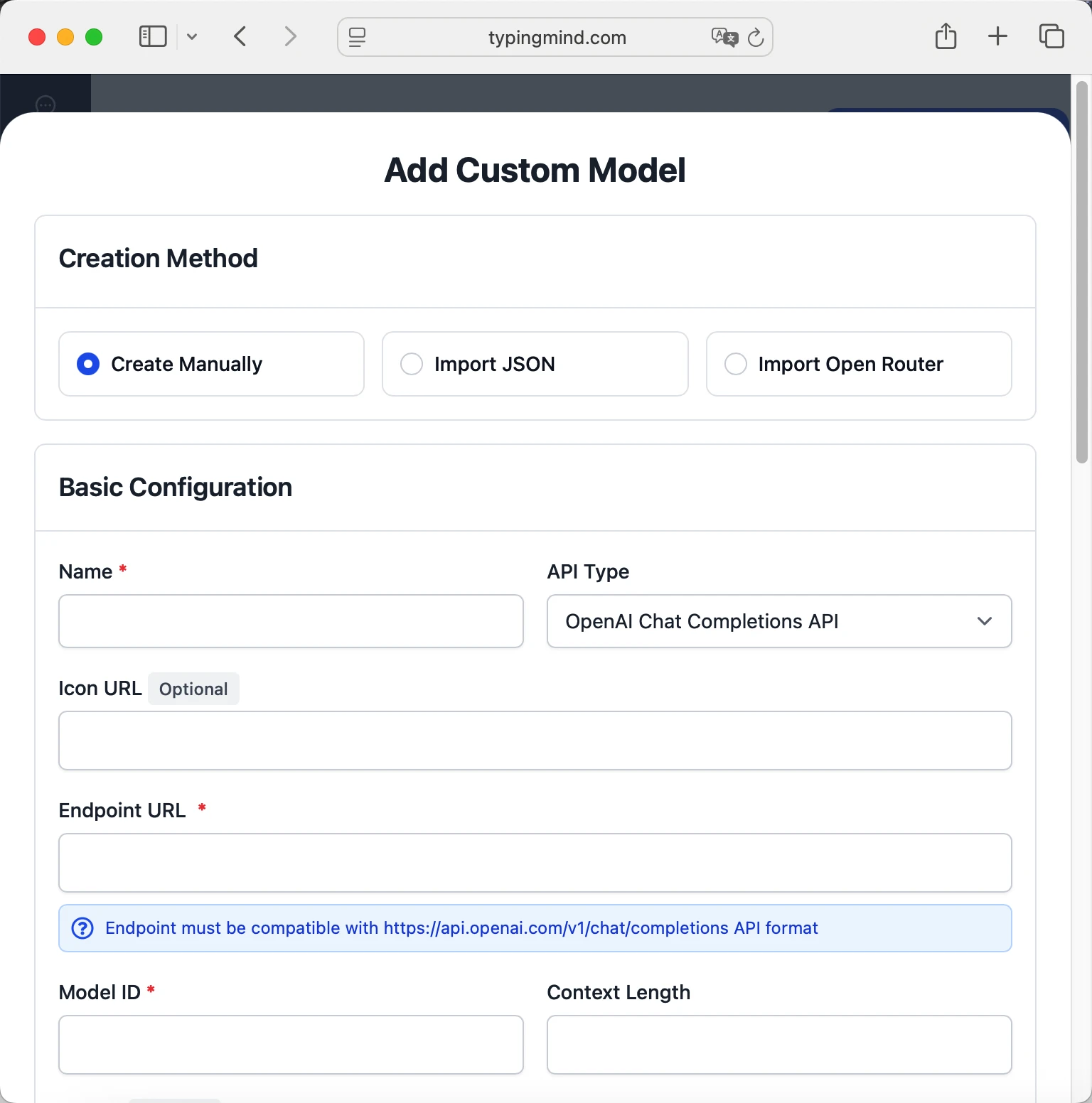 jina-deepsearch-v1https://deepsearch.jina.ai/v1/chat/completionsjina-deepsearch-v1 via Jina AIhttps://www.typingmind.com/model-logo.webp32000
jina-deepsearch-v1https://deepsearch.jina.ai/v1/chat/completionsjina-deepsearch-v1 via Jina AIhttps://www.typingmind.com/model-logo.webp32000 - Add custom headers by clicking "Add Custom Headers" in the Advanced Settings section:Authorization:
Bearer <JINA_API_KEY>:X-Title:typingmind.comHTTP-Referer:https://www.typingmind.com - Enable "Support Plugins (via OpenAI Functions)" if the model supports the "functions" or "tool_calls" parameter, or enable "Support OpenAI Vision" if the model supports vision.
- Click "Test" to verify the configuration
- If you see "Nice, the endpoint is working!", click "Add Model"
3. Start Chatting with Jina AI models
Now you can start chatting with Jina AI models through TypingMind:
- Select your preferred Jina AI model from the model dropdown menu
- Start typing your message in the chat input
- Enjoy faster responses and better features than the official interface
- Switch between different AI models as needed
- Use specific, detailed prompts for better responses (How to use Prompt Library)
- Create AI agents with custom instructions for repeated tasks (How to create AI Agents)
- Use plugins to extend Jina AI capabilities (How to use plugins)
- Upload documents and images directly to chat for AI analysis and discussion (Chat with documents)
4. Monitor Your AI Usage and Costs
One of the biggest advantages of using API keys with TypingMind is cost transparency and control. Unlike fixed subscriptions, you pay only for what you actually use. Visit https://jina.ai/api-dashboard/key-manager to monitor your Jina AI API usage and set spending limits.
- Use less expensive models for simple tasks
- Keep prompts concise but specific to reduce token usage
- Use TypingMind's prompt caching to reduce repeat costs (How to enable prompt caching)
- Using RAG (retrieval-augmented generation) for large documents to reduce repeat costs (How to use RAG)

Access Prime Intellect: INTELLECT-3 via OpenRouter
INTELLECT-3 is a 106B-parameter Mixture-of-Experts model (12B active) post-trained from GLM-4.5-Air-Base using supervised fine-tuning (SFT) followed by large-scale reinforcement learning (RL). It offers state-of-the-art performance for its size across math,...

Access TNG: R1T Chimera (free) via OpenRouter
TNG-R1T-Chimera is an experimental LLM with a faible for creative storytelling and character interaction. It is a derivate of the original TNG/DeepSeek-R1T-Chimera released in April 2025 and is available exclusively via Chutes and OpenRouter. Characteristics and improvements include: We think that it has a creative and pleasant personality. It has a preliminary EQ-Bench3 value of about 1305. It is quite a bit more intelligent than the original, albeit a slightly slower. It is much more think-token consistent, i.e. reasoning and answer blocks are properly delineated. Tool calling is much improved. TNG Tech, the model authors, ask that users follow the careful guidelines that Microsoft has created for their "MAI-DS-R1" DeepSeek-based model. These guidelines are available on Hugging Face (https://huggingface.co/microsoft/MAI-DS-R1).

Access TNG: R1T Chimera via OpenRouter
TNG-R1T-Chimera is an experimental LLM with a faible for creative storytelling and character interaction. It is a derivate of the original TNG/DeepSeek-R1T-Chimera released in April 2025 and is available exclusively via Chutes and OpenRouter. Characteristics and improvements include: We think that it has a creative and pleasant personality. It has a preliminary EQ-Bench3 value of about 1305. It is quite a bit more intelligent than the original, albeit a slightly slower. It is much more think-token consistent, i.e. reasoning and answer blocks are properly delineated. Tool calling is much improved. TNG Tech, the model authors, ask that users follow the careful guidelines that Microsoft has created for their "MAI-DS-R1" DeepSeek-based model. These guidelines are available on Hugging Face (https://huggingface.co/microsoft/MAI-DS-R1).

Access Anthropic: Claude Opus 4.5 via OpenRouter
Claude Opus 4.5 is Anthropic’s frontier reasoning model optimized for complex software engineering, agentic workflows, and long-horizon computer use. It offers strong multimodal capabilities, competitive performance across real-world coding and...

Access AllenAI: Olmo 3 32B Think via OpenRouter
Olmo 3 32B Think is a large-scale, 32-billion-parameter model purpose-built for deep reasoning, complex logic chains and advanced instruction-following scenarios. Its capacity enables strong performance on demanding evaluation tasks and...

Access AllenAI: Olmo 3 7B Instruct via OpenRouter
Olmo 3 7B Instruct is a supervised instruction-fine-tuned variant of the Olmo 3 7B base model, optimized for instruction-following, question-answering, and natural conversational dialogue. By leveraging high-quality instruction data and an open training pipeline, it delivers strong performance across everyday NLP tasks while remaining accessible and easy to integrate. Developed by Ai2 under the Apache 2.0 license, the model offers a transparent, community-friendly option for instruction-driven applications.

Access AllenAI: Olmo 3 7B Think via OpenRouter
Olmo 3 7B Think is a research-oriented language model in the Olmo family designed for advanced reasoning and instruction-driven tasks. It excels at multi-step problem solving, logical inference, and maintaining coherent conversational context. Developed by Ai2 under the Apache 2.0 license, Olmo 3 7B Think supports transparent, fully open experimentation and provides a lightweight yet capable foundation for academic research and practical NLP workflows.

Access Google: Nano Banana Pro (Gemini 3 Pro Image Preview) via OpenRouter
Nano Banana Pro is Google’s most advanced image-generation and editing model, built on Gemini 3 Pro. It extends the original Nano Banana with significantly improved multimodal reasoning, real-world grounding, and...

Access xAI: Grok 4.1 Fast via OpenRouter
Grok 4.1 Fast is xAI's best agentic tool calling model that shines in real-world use cases like customer support and deep research. 2M context window. Reasoning can be enabled/disabled using...

Access Google: Gemini 3 Pro Preview via OpenRouter
Gemini 3 Pro is Google’s flagship frontier model for high-precision multimodal reasoning, combining strong performance across text, image, video, audio, and code with a 1M-token context window. Reasoning Details must be preserved when using multi-turn tool calling, see our docs here: https://openrouter.ai/docs/use-cases/reasoning-tokens#preserving-reasoning-blocks. It delivers state-of-the-art benchmark results in general reasoning, STEM problem solving, factual QA, and multimodal understanding, including leading scores on LMArena, GPQA Diamond, MathArena Apex, MMMU-Pro, and Video-MMMU. Interactions emphasize depth and interpretability: the model is designed to infer intent with minimal prompting and produce direct, insight-focused responses. Built for advanced development and agentic workflows, Gemini 3 Pro provides robust tool-calling, long-horizon planning stability, and strong zero-shot generation for complex UI, visualization, and coding tasks. It excels at agentic coding (SWE-Bench Verified, Terminal-Bench 2.0), multimodal analysis, and structured long-form tasks such as research synthesis, planning, and interactive learning experiences. Suitable applications include autonomous agents, coding assistants, multimodal analytics, scientific reasoning, and high-context information processing.

Access Deep Cogito: Cogito v2.1 671B via OpenRouter
Cogito v2.1 671B MoE represents one of the strongest open models globally, matching performance of frontier closed and open models. This model is trained using self play with reinforcement learning...

Access OpenAI: GPT-5.1 via OpenRouter
GPT-5.1 is the latest frontier-grade model in the GPT-5 series, offering stronger general-purpose reasoning, improved instruction adherence, and a more natural conversational style compared to GPT-5. It uses adaptive reasoning...
