
About Synthetic
Synthetic.new is a privacy-focused AI platform offering private access to multiple open-source LLMs through simple flat-rate subscriptions starting at $20/month for 125 requests per 5 hours or $60/month for 1250 requests.
The platform provides access to 19+ always-on models including Llama 3 variants with up to 128K token context windows, specialized coding models, and task-specific LoRA adapters, with guaranteed privacy through no training on user data and automatic deletion within 14 days.
Key features include OpenAI-compatible API for integration with tools like Roo, Cline, and Octofriend, web-based chat interface, on-demand model launching from Hugging Face repositories on cloud GPUs with separate per-minute billing, predictable pricing without per-token charges, and support for large context coding tasks.
The platform prioritizes developer workflows and code generation with strong privacy guarantees and cost-effective access to powerful open-source models.
Step by step guide to use Synthetic API Key to chat with AI
1. Get Your Synthetic API Key
First, you'll need to obtain an API key from Synthetic. This key allows you to access their AI models directly and pay only for what you use.
- Visit Synthetic's API console
- Sign up or log in to your account
- Navigate to the API keys section
- Generate a new API key (copy it immediately as some providers only show it once)
- Save your API key in a secure password manager or encrypted note
2. Connect Your Synthetic API Key on TypingMind
Once you have your Synthetic API key, connecting it to TypingMind to chat with AI is straightforward:
- Open TypingMind in your browser
- Click the "Settings" icon (gear symbol)
- Navigate to "Models" section
- Click "Add Custom Model"
- Fill in the model information:Name:
hf:meta-llama/Llama-3.1-70B-Instruct via Synthetic(or your preferred name)Endpoint:https://api.synthetic.new/openai/v1/chat/completionsModel ID:hf:meta-llama/Llama-3.1-70B-Instructfor example (check Synthetic model list)Context Length: Enter the model's context window (e.g., 32000 for hf:meta-llama/Llama-3.1-70B-Instruct)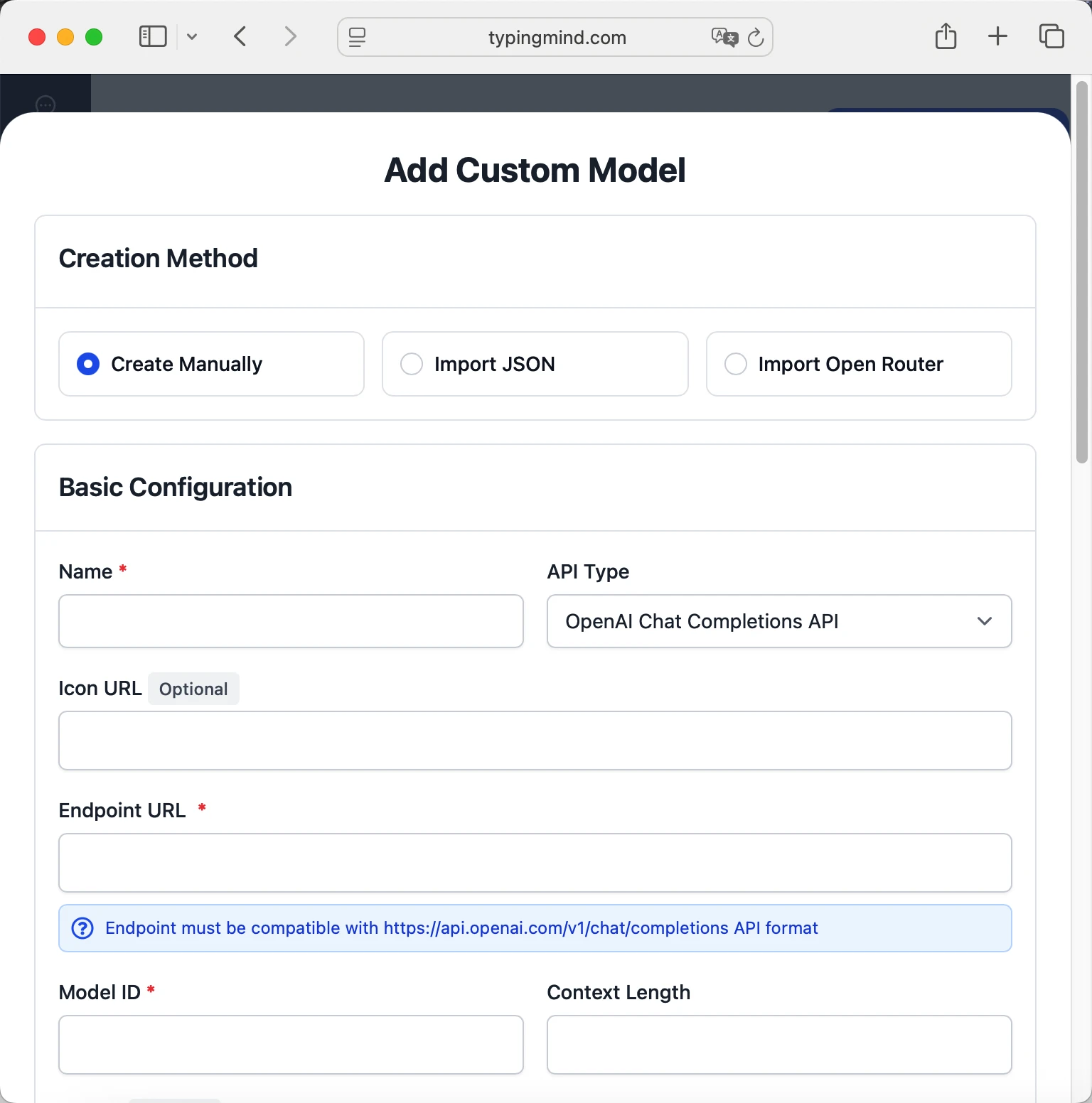 hf:meta-llama/Llama-3.1-70B-Instructhttps://api.synthetic.new/openai/v1/chat/completionshf:meta-llama/Llama-3.1-70B-Instruct via Synthetichttps://www.typingmind.com/model-logo.webp32000
hf:meta-llama/Llama-3.1-70B-Instructhttps://api.synthetic.new/openai/v1/chat/completionshf:meta-llama/Llama-3.1-70B-Instruct via Synthetichttps://www.typingmind.com/model-logo.webp32000 - Add custom headers by clicking "Add Custom Headers" in the Advanced Settings section:Authorization:
Bearer <SYNTHETIC_API_KEY>:X-Title:typingmind.comHTTP-Referer:https://www.typingmind.com - Enable "Support Plugins (via OpenAI Functions)" if the model supports the "functions" or "tool_calls" parameter, or enable "Support OpenAI Vision" if the model supports vision.
- Click "Test" to verify the configuration
- If you see "Nice, the endpoint is working!", click "Add Model"
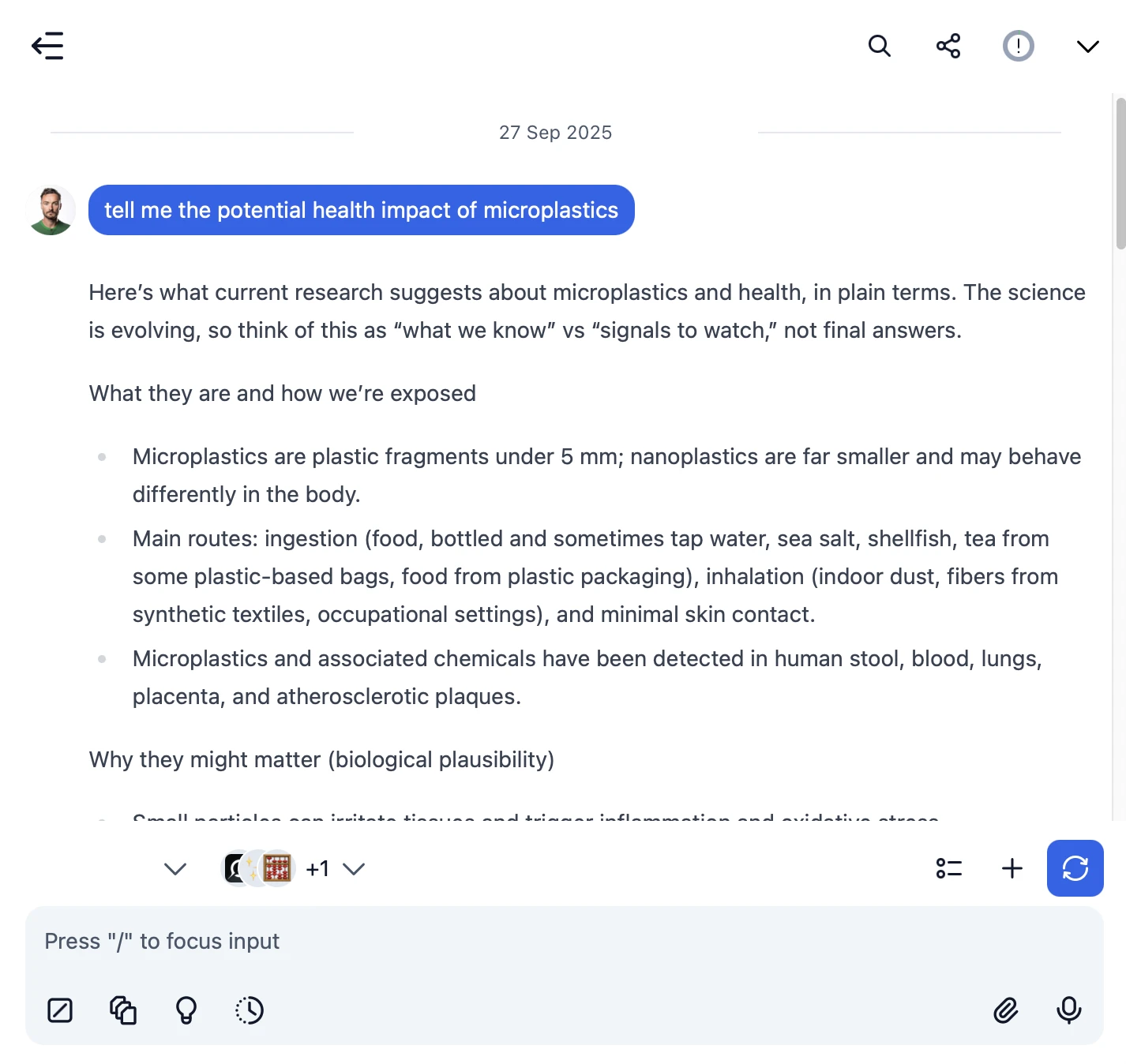
3. Start Chatting with Synthetic models
Now you can start chatting with Synthetic models through TypingMind:
- Select your preferred Synthetic model from the model dropdown menu
- Start typing your message in the chat input
- Enjoy faster responses and better features than the official interface
- Switch between different AI models as needed
- Use specific, detailed prompts for better responses (How to use Prompt Library)
- Create AI agents with custom instructions for repeated tasks (How to create AI Agents)
- Use plugins to extend Synthetic capabilities (How to use plugins)
- Upload documents and images directly to chat for AI analysis and discussion (Chat with documents)
4. Monitor Your AI Usage and Costs
One of the biggest advantages of using API keys with TypingMind is cost transparency and control. Unlike fixed subscriptions, you pay only for what you actually use. Visit https://synthetic.new/billing to monitor your Synthetic API usage and set spending limits.
- Use less expensive models for simple tasks
- Keep prompts concise but specific to reduce token usage
- Use TypingMind's prompt caching to reduce repeat costs (How to enable prompt caching)
- Using RAG (retrieval-augmented generation) for large documents to reduce repeat costs (How to use RAG)

Access AllenAI: Molmo2 8B via OpenRouter
Molmo2-8B is an open vision-language model developed by the Allen Institute for AI (Ai2) as part of the Molmo2 family, supporting image, video, and multi-image understanding and grounding. It is based on Qwen3-8B and uses SigLIP 2 as its vision backbone, outperforming other open-weight, open-data models on short videos, counting, and captioning, while remaining competitive on long-video tasks.

Access AllenAI: Olmo 3.1 32B Instruct via OpenRouter
Olmo 3.1 32B Instruct is a large-scale, 32-billion-parameter instruction-tuned language model engineered for high-performance conversational AI, multi-turn dialogue, and practical instruction following. As part of the Olmo 3.1 family, this...

Access Xiaomi: MiMo-V2-Flash via OpenRouter
MiMo-V2-Flash is an open-source foundation language model developed by Xiaomi. It is a Mixture-of-Experts model with 309B total parameters and 15B active parameters, adopting hybrid attention architecture. MiMo-V2-Flash supports a...

Access Nex AGI: DeepSeek V3.1 Nex N1 via OpenRouter
DeepSeek V3.1 Nex-N1 is the flagship release of the Nex-N1 series — a post-trained model designed to highlight agent autonomy, tool use, and real-world productivity. Nex-N1 demonstrates competitive performance across...

Access Qwen: Qwen3 Next 80B A3B Instruct (free) via OpenRouter
Qwen3-Next-80B-A3B-Instruct is an instruction-tuned chat model in the Qwen3-Next series optimized for fast, stable responses without “thinking” traces. It targets complex tasks across reasoning, code generation, knowledge QA, and multilingual...

Access ByteDance Seed: Seed-2.0-Lite via OpenRouter
Seed-2.0-Lite is a versatile, cost‑efficient enterprise workhorse that delivers strong multimodal and agent capabilities while offering noticeably lower latency, making it a practical default choice for most production workloads across...

Access Qwen: Qwen3.5-9B via OpenRouter
Qwen3.5-9B is a multimodal foundation model from the Qwen3.5 family, designed to deliver strong reasoning, coding, and visual understanding in an efficient 9B-parameter architecture. It uses a unified vision-language design...

Access xAI: Grok 4.20 Multi-Agent Beta via OpenRouter
Grok 4.20 Multi-Agent Beta is a variant of xAI’s Grok 4.20 designed for collaborative, agent-based workflows. Multiple agents operate in parallel to conduct deep research, coordinate tool use, and synthesize information across complex tasks. Reasoning effort behavior: - low / medium: 4 agents - high / xhigh: 16 agents

Access xAI: Grok 4.20 Beta via OpenRouter
Grok 4.20 Beta is xAI's newest flagship model with industry-leading speed and agentic tool calling capabilities. It combines the lowest hallucination rate on the market with strict prompt adherance, delivering consistently precise and truthful responses. Reasoning can be enabled/disabled using the `reasoning` `enabled` parameter in the API. [Learn more in our docs](https://openrouter.ai/docs/use-cases/reasoning-tokens#controlling-reasoning-tokens)
Access Hunter Alpha via OpenRouter
Hunter Alpha is a 1 Trillion parameter + 1M token context frontier intelligence model built for agentic use. It excels at long-horizon planning, complex reasoning, and sustained multi-step task execution, with the reliability and instruction-following precision that frameworks like OpenClaw need. **Note:** All prompts and completions for this model are logged by the provider and may be used to improve the model.

Access Healer Alpha via OpenRouter
Healer Alpha is a frontier omni-modal model with vision, hearing, reasoning, and action capabilities. It brings the full power of agentic intelligence into the real world: natively perceiving visual and audio inputs, reasoning across modalities, and executing complex multi-step tasks with precision and reliability. **Note:** All prompts and completions for this model are logged by the provider and may be used to improve the model.

Access NVIDIA: Nemotron 3 Super (free) via OpenRouter
NVIDIA Nemotron 3 Super is a 120B-parameter open hybrid MoE model, activating just 12B parameters for maximum compute efficiency and accuracy in complex multi-agent applications. Built on a hybrid Mamba-Transformer...
