
How to use MiniMax M2.5 from Venice AI with API Key on TypingMind
Learn how to access and use MiniMax M2.5 with your Venice AI API key through TypingMind. Get started with this powerful AI model in minutes.
Venice.ai is a privacy-first, uncensored AI platform providing access to leading open-source models without data collection, content restrictions, or conversation logging.
Key features include private access to multiple models (Llama, DeepSeek, StableDiffusion, GPT, Claude, Gemini), zero data retention with local chat history storage, decentralized GPU infrastructure preventing single-entity data access, uncensored text generation and image creation, web-enabled research and PDF analysis, and a private API with no logging. The platform serves over 1.3 million users and is integrating Web3 capabilities through partnerships like Warden Protocol for on-chain AI and censorship resistance.
Venice offers both free and Pro tiers with mobile apps available, focusing on creative freedom and honest answers without guardrails while maintaining complete conversation privacy through decentralized processing.
Official Documentation: https://docs.venice.ai
MiniMax M2.5 Overview
| Model Name | MiniMax M2.5 |
| Provider | Venice AI |
| Model ID | minimax-m25 |
| Release Date | Feb 12, 2026 |
| Last Updated | Apr 12, 2026 |
| Context Window | 198,000 tokens |
| Max Output | 32,768 tokens |
| Pricing /1M tokens | $0.34 input $1.19 output $0.04 cache read |
| Input Modalities | text |
| Output Modalities | text |
| Capabilities | ReasoningTool CallingTemperature Control |
Complete Setup Guide
Get Your Venice AI API Key
First, you'll need to obtain an API key from Venice AI. This key allows you to access their AI models directly and pay only for what you use.
- Visit Venice AI's API console
- Sign up or log in to your account
- Navigate to the API keys section
- Generate a new API key (copy it immediately as some providers only show it once)
- Save your API key in a secure password manager or encrypted note
⚠️ Important: Keep your API key secure and never share it publicly. Store it safely as you'll need it to connect with TypingMind.
Configure TypingMind with Venice AI API Key
- Open TypingMind in your browser
- Click the "Settings" icon (gear symbol)
- Navigate to "Models" section
- Click "Add Custom Model"
- Fill in the model information:Name:
minimax-m25 via Venice AI(or your preferred name)Endpoint:https://api.venice.ai/api/v1/chat/completionsModel ID:minimax-m25Context Length: Enter the model's context window (e.g., 198000 for minimax-m25)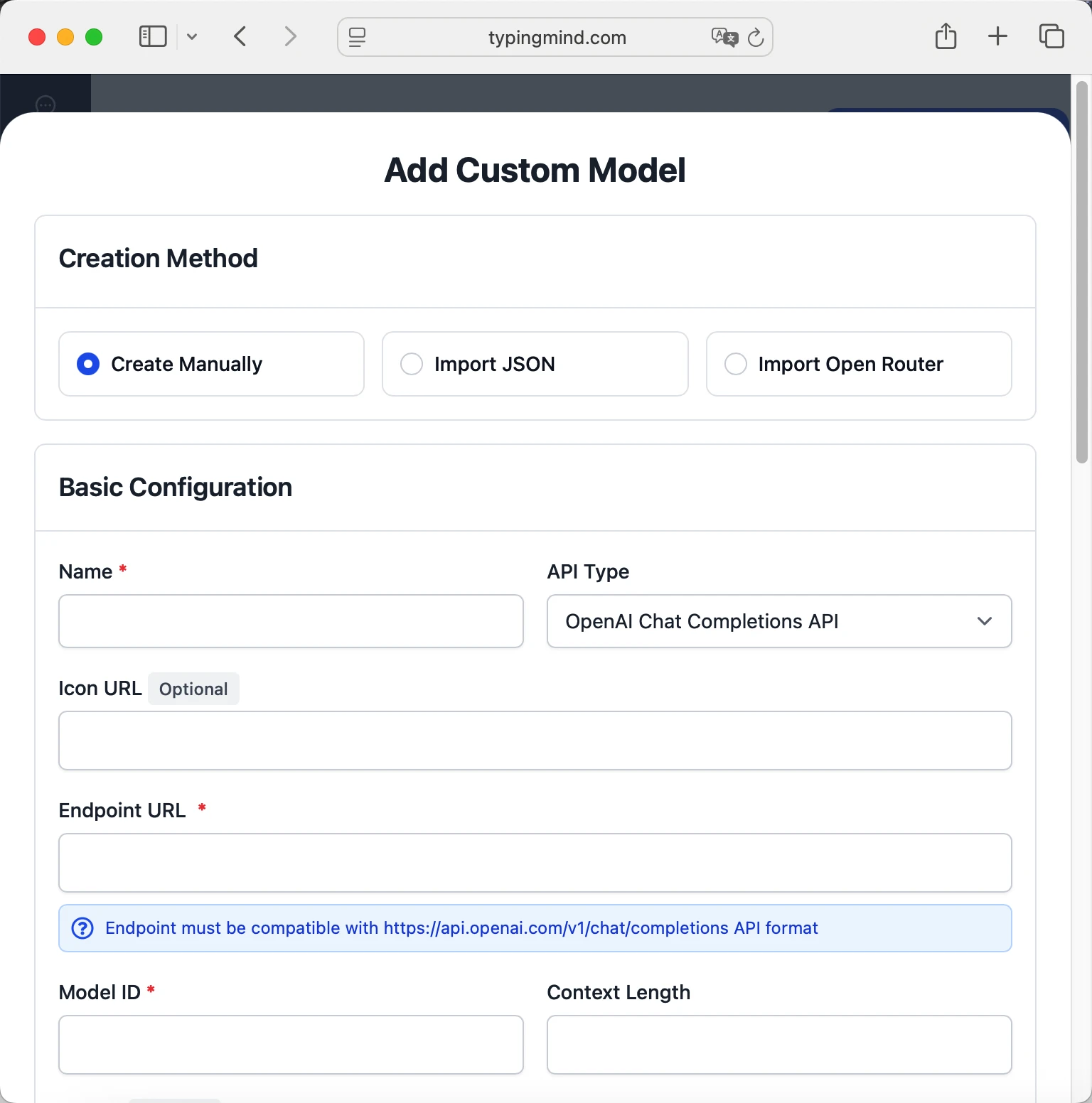 minimax-m25https://api.venice.ai/api/v1/chat/completionsminimax-m25 via Venice AIhttps://www.typingmind.com/model-logo.webp198000
minimax-m25https://api.venice.ai/api/v1/chat/completionsminimax-m25 via Venice AIhttps://www.typingmind.com/model-logo.webp198000 - Add custom headers by clicking "Add Custom Headers" in the Advanced Settings section:Authorization:
Bearer <VENICE_API_KEY>:X-Title:typingmind.comHTTP-Referer:https://www.typingmind.com - Enable "Support Plugins (via OpenAI Functions)" if the model supports the "functions" or "tool_calls" parameter, or enable "Support OpenAI Vision" if the model supports vision.
- Click "Test" to verify the configuration
- If you see "Nice, the endpoint is working!", click "Add Model"
Start chatting with MiniMax M2.5
Now you can start chatting with MiniMax M2.5 through TypingMind:
- Select MiniMax M2.5 from the model dropdown menu
- Start typing your message in the chat input
- Enjoy faster responses and better features than the official interface
- Switch between different AI models as needed
💡 Pro tips for better results:
- Use specific, detailed prompts for better responses (How to use Prompt Library)
- Create AI agents with custom instructions for repeated tasks (How to create AI Agents)
- Use plugins to extend MiniMax M2.5 capabilities (How to use plugins)
Frequently Asked Questions
Do I need a subscription to use MiniMax M2.5?
No! With Venice AI API, you pay only for what you use with no monthly subscription. Add credits to your Venice AI account and pay as you go. TypingMind is also a one-time purchase, not a subscription.
How much will it cost to use MiniMax M2.5?
MiniMax M2.5 costs $0.34/1M input tokens and $1.19/1M output tokens. A typical conversation might cost $0.01-0.10 depending on length.
Can I use other models besides MiniMax M2.5?
Yes! With Venice AI API + TypingMind, you can access all Venice AI models. Switch between them instantly in TypingMind.
Is my data private and secure?
Yes! TypingMind stores conversations locally (web version in browser, desktop version on your device). Venice AI handles API calls securely. Check Venice AI's data policy for specifics.
Can I use MiniMax M2.5 for commercial projects?
Yes! Check Venice AI's terms of service for specific commercial use policies. TypingMind supports commercial use.

Use Grok 4.1 Fast from venice with API Key
Grok 4.1 Fast from Venice AI - Context: 1000000 tokens

Use Qwen 3 235B A22B Instruct 2507 from venice with API Key
Qwen 3 235B A22B Instruct 2507 from Venice AI - Context: 128000 tokens

Use Gemini 3 Flash Preview from venice with API Key
Gemini 3 Flash Preview from Venice AI - Context: 256000 tokens

Use Claude Opus 4.5 from venice with API Key
Claude Opus 4.5 from Venice AI - Context: 198000 tokens

Use Venice Medium from venice with API Key
Venice Medium from Venice AI - Context: 128000 tokens

Use Grok Code Fast 1 from venice with API Key
Grok Code Fast 1 from Venice AI - Context: 256000 tokens

Use GLM 4.7 from venice with API Key
GLM 4.7 from Venice AI - Context: 198000 tokens

Use Venice Uncensored 1.1 from venice with API Key
Venice Uncensored 1.1 from Venice AI - Context: 32000 tokens

Use Gemini 3 Pro Preview from venice with API Key
Gemini 3 Pro Preview from Venice AI - Context: 198000 tokens

Use GPT-5.2 from venice with API Key
GPT-5.2 from Venice AI - Context: 256000 tokens

Use Venice Small from venice with API Key
Venice Small from Venice AI - Context: 32000 tokens

Use Llama 3.3 70B from venice with API Key
Llama 3.3 70B from Venice AI - Context: 128000 tokens
