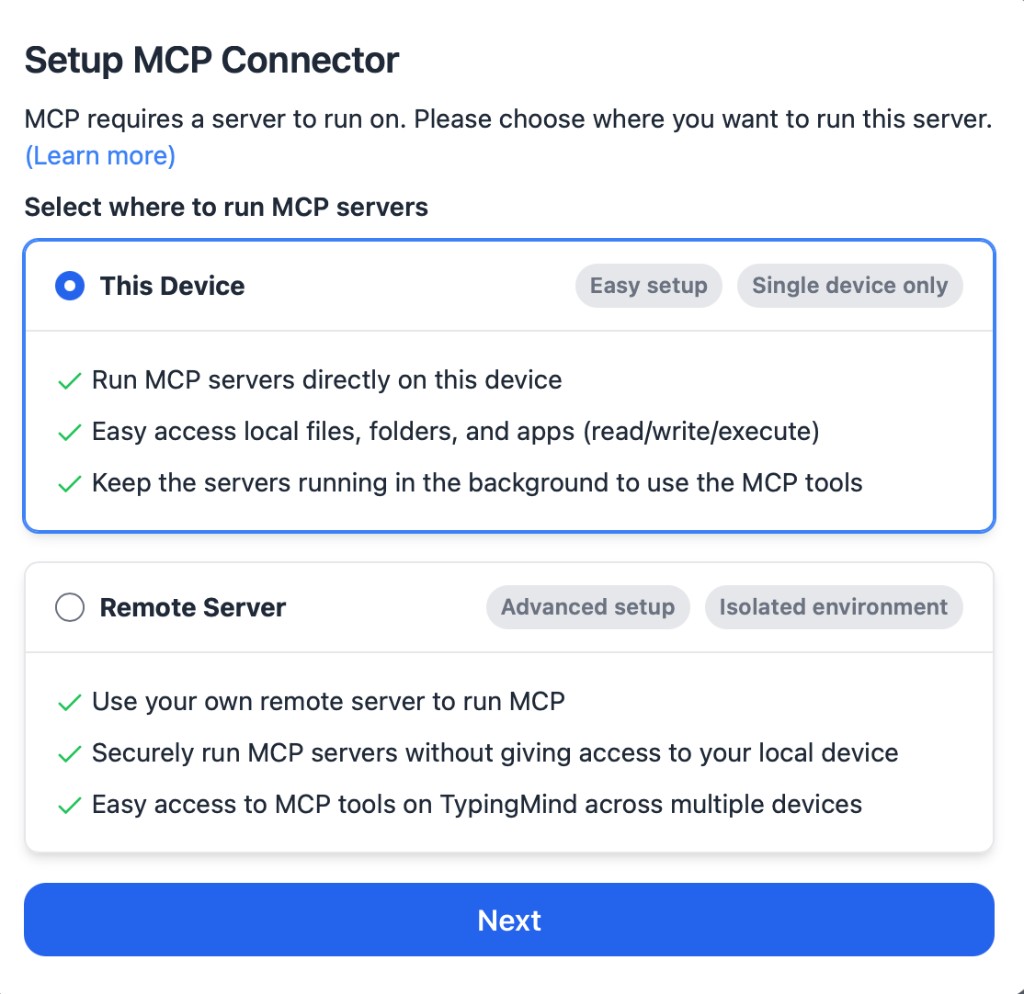
@houtini/lm Houtini LM - Save Tokens by Offloading Tasks from Claude Code to Your Local LLM Server (LM Studio / Ollama), Openrouter or a Cloud API

![]()
Quick Navigation
How it works | Quick start | What gets offloaded | Tools | Performance tracking | Structured JSON output | Model routing | Self-test (shakedown) | Configuration | Compatible endpoints | Developer guide
I built this because I kept leaving Claude Code running overnight on big refactors and the token bill was painful. A huge chunk of that spend goes on bounded tasks any decent model handles fine - generating boilerplate, code review, commit messages, format conversion. Stuff that doesn't need Claude's reasoning or tool access.
Houtini LM connects Claude Code to a local LLM on your network - or any OpenAI-compatible API (LM Studio, Ollama, vLLM, DeepSeek, Groq, Cerebras, and OpenRouter's 300+ models through one endpoint). Claude keeps doing the hard work - architecture, planning, multi-file changes - and offloads the grunt work to whatever cheaper model you've got running. No Claude quota burn. No rate limits. Private if local, cheap if cloud. The trade is wall-clock time: local inference is typically 3-30× slower than frontier models, so delegation wins on bounded, self-contained tasks rather than everything.
I wrote a full walkthrough of why I built this and how I use it day to day.
How it works
Claude Code (orchestrator) | |-- Complex reasoning, planning, architecture --> Claude API (your tokens) | +-- Bounded grunt work --> houtini-lm --HTTP/SSE--> Your local LLM (free) . Boilerplate & test stubs Qwen, Llama, Nemotron, GLM... . Code review & explanations LM Studio, Ollama, vLLM, llama.cpp . Commit messages & docs DeepSeek, Groq, Cerebras (cloud) . Format conversion . Mock data & type definitions . Embeddings for RAG pipelines
Claude's the architect. Your local model's the drafter. Claude QAs everything.
Quick start
Claude Code
bashclaude mcp add houtini-lm -- npx -y @houtini/lm
That's it. If LM Studio's running on localhost:1234 (the default), Claude can start delegating straight away.
LLM on a different machine
I've got a GPU box on my local network running Qwen 3 Coder Next in LM Studio. If you've got a similar setup, point the URL at it:
bashclaude mcp add houtini-lm -e HOUTINI_LM_ENDPOINT_URL=http://192.168.1.50:1234 -- npx -y @houtini/lm
Cloud APIs
Works with anything speaking the OpenAI format. DeepSeek at twenty-eight cents per million tokens, Groq for speed, Cerebras if you want three thousand tokens per second - whatever you fancy:
bashclaude mcp add houtini-lm \ -e HOUTINI_LM_ENDPOINT_URL=https://api.deepseek.com \ -e HOUTINI_LM_API_KEY=your-key-here \ -- npx -y @houtini/lm
OpenRouter
OpenRouter gives you 300+ models through one endpoint. Auto-detected from the URL — attribution headers, reasoning.exclude, and retry-with-backoff all kick in automatically:
bashclaude mcp add houtini-lm \ -e HOUTINI_LM_ENDPOINT_URL=https://openrouter.ai/api \ -e HOUTINI_LM_API_KEY=sk-or-v1-... \ -e HOUTINI_LM_MODEL=nvidia/nemotron-3-nano-30b-a3b:free \ -- npx -y @houtini/lm
Claude Desktop
Drop this into your claude_desktop_config.json:
json{ "mcpServers": { "houtini-lm": { "command": "npx", "args": ["-y", "@houtini/lm"], "env": { "HOUTINI_LM_ENDPOINT_URL": "http://localhost:1234" } } } }
Model discovery
This is where things get interesting. At startup, houtini-lm queries your LLM server for every model available - loaded and downloaded - then looks each one up on HuggingFace's free API to pull metadata: architecture, licence, download count, pipeline type. All of that gets cached in a local SQLite database (~/.houtini-lm/model-cache.db) so subsequent startups are instant.
The result is that houtini-lm actually knows what your models are good at. Not just the name - the capabilities, the strengths, what tasks to send where. If you've got Nemotron loaded but a Qwen Coder sitting idle, it'll flag that. If someone on a completely different setup loads a Mistral model houtini-lm has never seen before, the HuggingFace lookup auto-generates a profile for it.
Run list_models and you get the full picture:
Loaded models (ready to use): nvidia/nemotron-3-nano type: llm, arch: nemotron_h_moe, quant: Q4_K_M, format: gguf context: 200,082 (max 1,048,576), by: nvidia Capabilities: tool_use NVIDIA Nemotron: compact reasoning model optimised for step-by-step logic Best for: analysis tasks, code bug-finding, math/science questions HuggingFace: text-generation, 1.7M downloads, MIT licence Available models (downloaded, not loaded): qwen3-coder-30b-a3b-instruct type: llm, arch: qwen3moe, quant: BF16, context: 262,144 Qwen3 Coder: code-specialised model with agentic capabilities Best for: code generation, code review, test stubs, refactoring HuggingFace: text-generation, 12.9K downloads, Apache-2.0
For models we know well - Qwen, Nemotron, Granite, LLaMA, GLM, GPT-OSS - there's a curated profile built in with specific strengths and weaknesses. For everything else, the HuggingFace lookup fills the gaps. Cache refreshes every 7 days. Zero friction - sql.js is pure WASM, no native dependencies, no build tools needed.
What gets offloaded
Delegate to the local model - bounded, well-defined tasks:
| Task | Why it works locally |
|---|---|
| Generate test stubs | Clear input (source), clear output (tests) |
| Explain a function | Summarisation doesn't need tool access |
| Draft commit messages | Diff in, message out |
| Code review | Paste full source, ask for bugs |
| Convert formats | JSON to YAML, snake_case to camelCase |
| Generate mock data | Schema in, data out |
| Write type definitions | Source in, types out |
| Structured JSON output | Grammar-constrained, guaranteed valid |
| Text embeddings | Semantic search, RAG pipelines |
| Brainstorm approaches | Doesn't commit to anything |
Keep on Claude - anything that needs reasoning, tool access, or multi-step orchestration:
- Architectural decisions
- Reading/writing files
- Running tests and interpreting results
- Multi-file refactoring plans
- Anything that needs to call other tools
The tool descriptions are written to nudge Claude into planning delegation at the start of large tasks, not just using it when it happens to think of it.
Performance tracking
Every response includes a footer with real performance data — computed from the SSE stream, not from any proprietary API:
--- Model: nvidia/nemotron-3-nano | 279→303 tokens (12 reasoning / 291 visible) | TTFT: 485ms, 58.0 tok/s, 5.2s 📊 First measured call on nvidia/nemotron-3-nano: 58.0 tok/s, 485ms to first token — use this to gauge whether to delegate longer tasks. 💰 Claude quota saved — this session: 4,283 tokens / 7 calls · lifetime: 147,432 tokens / 213 calls
The 📊 line only appears on the first measured call per model per session — it's a real benchmark from a genuine task, not a synthetic warmup. The 💰 line updates every call.
When the active model returns completion_tokens_details.reasoning_tokens (DeepSeek R1, LM Studio with "Separate reasoning_content" enabled, OpenAI reasoning models), the token block splits into reasoning / visible so you can see when a thinking model is burning its output budget on hidden reasoning.
Lifetime persistence
Per-model performance and token counts persist across Claude Desktop restarts in ~/.houtini-lm/model-cache.db. This means:
- From call 1 of a new session,
discovershows historical tok/s and TTFT for the loaded model — not "not yet benchmarked". - The 💰 counter shows both session and lifetime totals.
- The
code_task_filespre-flight estimator uses measured per-model prefill rate to refuse obviously-too-large inputs with a clear diagnostic, instead of letting them silently hang against the MCP client timeout.
The data is workstation-specific — that's intentional. Routing decisions should reflect your actual hardware, not a synthetic benchmark.
The discover tool shows per-model averages across both scopes:
Measured speed (session): 58.0 tok/s · TTFT 485ms (1 call) Measured speed (lifetime on this workstation): 46.9 tok/s · TTFT 2641ms (214 calls, last used 2026-04-20)
In practice, Claude delegates more aggressively the longer a session runs. After about 5,000 offloaded tokens, it starts hunting for more work to push over. Reinforcing loop.
Model routing
If you've got multiple models loaded (or downloaded), houtini-lm picks the best one for each task automatically. Each model family has per-family prompt hints - temperature, output constraints, and think-block flags - so GLM gets told "no preamble, no step-by-step reasoning" while Qwen Coder gets a low temperature for focused code output.
The routing scores loaded models against the task type (code, chat, analysis, embedding). If the best loaded model isn't ideal for the task, you'll see a suggestion in the response footer pointing to a better downloaded model. No runtime model swapping - model loading takes minutes, so houtini-lm suggests rather than blocks.
Supported model families with curated prompt hints: GLM-4, Qwen3 Coder, Qwen3, LLaMA 3, Nemotron, Granite, GPT-OSS, Nomic Embed. Unknown models get sensible defaults.
Overriding the router
Scoring works well when there are a handful of loaded models. On providers with large catalogues (OpenRouter lists 300+ models, all reporting as routable) unknown models all score zero and ties break on iteration order, so you probably want to pin explicitly. Two ways, in precedence order:
- Per-call — pass
model: "nvidia/nemotron-3-nano-30b-a3b:free"to any ofchat/custom_prompt/code_task/code_task_files. Overrides everything else. - Per-process — set
HOUTINI_LM_MODELin the environment. Applies to every tool call from that server process. Overridden by the per-call parameter.
Leave both unset and the router picks.
Tools
chat
The workhorse. Send a task, get an answer. The description includes planning triggers that nudge Claude to identify offloadable work when it's starting a big task.
| Parameter | Required | Default | What it does |
|---|---|---|---|
message | yes | - | The task. Be specific about output format. |
system | no | - | Persona - "Senior TypeScript dev" not "helpful assistant" |
temperature | no | 0.3 | 0.1 for code, 0.3 for analysis, 0.7 for creative |
max_tokens | no | auto | Defaults to 25% of the loaded model's context window (fallback 16,384). Pass a number to cap it. |
json_schema | no | - | Force structured JSON output conforming to a schema |
model | no | auto-route | Pin a specific model id (e.g. nvidia/nemotron-3-nano-30b-a3b:free on OpenRouter). Overrides routing and HOUTINI_LM_MODEL. Useful on providers with many candidates. |
custom_prompt
Three-part prompt: system, context, instruction. Keeping them separate prevents context bleed - consistently outperforms stuffing everything into one message, especially with local models. I tested this properly one weekend - took the same batch of review tasks and ran them both ways. Splitting things into three parts won every round.
| Parameter | Required | Default | What it does |
|---|---|---|---|
instruction | yes | - | What to produce. Under 50 words works best. |
system | no | - | Persona + constraints, under 30 words |
context | no | - | Complete data to analyse. Never truncate. |
temperature | no | 0.3 | 0.1 for review, 0.3 for analysis |
max_tokens | no | auto | Defaults to 25% of the loaded model's context window (fallback 16,384). |
json_schema | no | - | Force structured JSON output |
model | no | auto-route | Pin a specific model id. Overrides routing and HOUTINI_LM_MODEL. |
code_task
Built for code analysis. Pre-configured system prompt with temperature and output constraints tuned per model family via the routing layer.
| Parameter | Required | Default | What it does |
|---|---|---|---|
code | yes | - | Complete source code. Never truncate. |
task | yes | - | "Find bugs", "Explain this", "Write tests" |
language | no | - | "typescript", "python", "rust", etc. |
max_tokens | no | auto | Defaults to 25% of the loaded model's context window (fallback 16,384). |
model | no | auto-route | Pin a specific model id. Overrides routing and HOUTINI_LM_MODEL. |
code_task_files
Like code_task, but the local LLM reads files directly from disk — source never passes through the MCP client's context window. Use this when reviewing multiple related files, or a single large file that's awkward to paste. Files are read in parallel with Promise.allSettled, so one unreadable file doesn't sink the call; failures are surfaced inline with the reason.
Includes a pre-flight prefill estimator: if measured per-model data from the SQLite cache shows the input would exceed the MCP client's ~60s request-timeout during prompt processing, the call is refused early with a concrete diagnostic (estimated prefill seconds, tokens, and sample-count) instead of letting it silently hang. First-time callers are never refused — the estimator only fires after ≥2 measured samples.
| Parameter | Required | Default | What it does |
|---|---|---|---|
paths | yes | - | Array of absolute file paths. Relative paths are rejected. |
task | yes | - | "Find bugs across these files", "Audit this module" |
language | no | - | "typescript", "python", "rust", etc. |
max_tokens | no | auto | Defaults to 25% of the loaded model's context window (fallback 16,384). |
model | no | auto-route | Pin a specific model id. Overrides routing and HOUTINI_LM_MODEL. |
embed
Generate text embeddings via the OpenAI-compatible /v1/embeddings endpoint. Requires an embedding model to be available - Nomic Embed is a solid choice. Returns the vector, dimension count, and usage stats.
| Parameter | Required | Default | What it does |
|---|---|---|---|
input | yes | - | Text to embed |
model | no | auto | Embedding model ID |
discover
Health check and speed readout. Returns model name, context window, capability profile, connection latency (labelled explicitly — this is the /v1/models fetch round-trip, not inference speed), and the active model's measured tok/s and TTFT averaged over the session. Before any real call has run, measured speed shows as "not yet benchmarked — will be captured on the first real call" rather than inventing a number from a synthetic probe. Call before delegating if you're not sure the LLM's available, or when deciding whether a longer task is worth offloading.
list_models
Lists everything on the LLM server - loaded and downloaded - with full metadata: architecture, quantisation, context window, capabilities, and HuggingFace enrichment data. Shows capability profiles describing what each model is best at, so Claude can make informed delegation decisions.
stats
Compact markdown dump of your offload stats — session and lifetime totals, per-model performance history, reasoning-token overhead — without the model catalog that discover prints. Cheap to call repeatedly to watch the 💰 counter climb.
| Parameter | Required | Default | What it does |
|---|---|---|---|
model | no | - | Filter output to a single model ID. Omit for all models ever used on this workstation. |
Example output:
## Houtini LM stats **Endpoint**: http://hopper:1234 (LM Studio) **First call on this workstation**: 2026-04-14 ### Totals | Scope | Calls | Prompt tokens | Completion tokens | Total tokens | | Session | 7 | 3,100 | 1,183 | 4,283 | | Lifetime | 213 | — | — | 147,432 | ### Per-model performance | Model | Scope | Calls | Avg TTFT | Avg tok/s | Prompt tokens | Last used | | nvidia/nemotron-3-nano | session | 7 | 485 | 58.0 | — | — | | nvidia/nemotron-3-nano | lifetime | 213 | 2641 | 46.9 | 89,320 | 2026-04-20 | ### Reasoning-token overhead (lifetime) 124 / 47,183 completion tokens spent on hidden reasoning (0.3%). Low — reasoning is effectively suppressed.
The reasoning-token overhead line is the canary for "is reasoning_effort actually being honoured on this model and this backend?" — above ~30% is a signal to investigate.
Structured JSON output
Both chat and custom_prompt accept a json_schema parameter that forces the response to conform to a JSON Schema. LM Studio uses grammar-based sampling to guarantee valid output - no hoping the model remembers to close its brackets.
json{ "json_schema": { "name": "code_review", "schema": { "type": "object", "properties": { "issues": { "type": "array", "items": { "type": "object", "properties": { "line": { "type": "number" }, "severity": { "type": "string" }, "description": { "type": "string" } }, "required": ["line", "severity", "description"] } } }, "required": ["issues"] } } }
Getting good results from local models
Qwen, Llama, Nemotron, GLM - they score brilliantly on coding benchmarks now. The gap between a good and bad result is almost always prompt quality, not model capability. I've spent a fair bit of time on this.
Send complete code. Local models hallucinate details when you give them truncated input. If a file's too large, send the relevant function - not a snippet with ... in the middle.
Be explicit about output format. "Return a JSON array" or "respond in bullet points" - don't leave it open-ended. Smaller models need this.
Set a specific persona. "Expert Rust developer who cares about memory safety" gets noticeably better results than "helpful assistant."
State constraints. "No preamble", "reference line numbers", "max 5 bullet points" - tell the model what not to do as well as what to do.
Include surrounding context. For code generation, send imports, types, and function signatures - not just the function body.
One call at a time. As of v2.8.0, houtini-lm enforces this automatically with a request semaphore. Parallel calls queue up and run one at a time, so each gets the full timeout budget instead of stacking.
Self-test (shakedown)
The canonical way to verify an install and get an honest read on what the loaded model can do on your hardware:
bashnpm run shakedown
This runs shakedown.mjs — an end-to-end test that exercises all seven tools (discover → list_models → chat → custom_prompt → code_task → code_task_files → embed) and prints a summary table with real TTFT, tok/s, token counts, and reasoning-token split for each call. Takes under a minute on a decent rig.
Sample output tail:
Summary 7/7 steps passed on LM Studio, model=nvidia/nemotron-3-nano | Tool | OK | TTFT (ms) | tok/s | Tokens in→out | Reasoning | Notes | chat | ✅ | 891 | 36.9 | 48→104 | — | answered | custom_prompt | ✅ | 872 | 43.9 | 170→333 | — | 5 valid items | code_task | ✅ | 857 | 41.6 | 180→189 | — | tests generated | code_task_files | ✅ | 11028 | 39.5 | 6891→3000 | — | cross-referenced | embed | ✅ | — | — | — | — | 768-dim vector Tokens offloaded: 10,915 (prompt: 7,289, completion: 3,626, reasoning: 0)
Want a human-readable quality review rather than just latency numbers? Paste SHAKEDOWN.md into a Claude session that has houtini-lm attached — Claude will drive the seven steps and write you a report on output quality as well as performance.
Think-block handling
Thinking models burn part of their output budget on invisible reasoning before producing an answer. Left alone, small models at default max_tokens will happily spend the whole budget reasoning and return an empty body. How houtini-lm handles this depends on whether the provider exposes reasoning as a separate channel or in-band.
Local backends (LM Studio, Ollama, vLLM) — reasoning arrives inline on the content channel or via delta.reasoning_content / delta.reasoning:
- Suppression at source — at startup, houtini-lm checks each model's HuggingFace chat template for thinking support. Models that support the
enable_thinkingtoggle (Qwen3, Gemma 4, Nemotron, DeepSeek R1, GLM-4, gpt-oss) get thinking disabled at inference time. Detection is automatic via chat-template inspection plus arch/id heuristics, so Ollama tags likeqwen3:4bare recognised too. - Budget inflation —
max_tokensis silently inflated (×4 or +2000, whichever is bigger) so reasoning can't starve the content channel. Essential for backends like Ollama where the Qwen3 Jinja template hardcodesenable_thinking=trueand ignores the API flag. - Reasoning capture + stripping — reasoning is captured from both
delta.reasoning_content(LM Studio, DeepSeek R1, Nemotron) anddelta.reasoning(Ollama). Inline<think>...</think>blocks on the content channel are stripped after assembly — balanced pairs, orphan openers, and orphan closers are all handled. When reasoning exhausts the budget entirely, the captured reasoning text is returned as a last-ditch fallback so the caller sees something rather than a silent empty body.
OpenRouter — handles reasoning as a structured per-request parameter and a separate message.reasoning response field. Houtini-lm sends reasoning: { exclude: true } on every OpenRouter call so thinking models (Nemotron, DeepSeek R1, Qwen3, Claude thinking, gpt-oss, etc.) are normalised to text-only output at the provider level. Budget inflation still fires because some upstream providers bill reasoning tokens against the cap before exclude filtering. No stripping is needed — the provider never sends the reasoning in the first place.
The quality footer flags think-blocks-stripped when stripping occurred, reasoning-only when the fallback fired, and hit-max-tokens when the budget ran out — so you know exactly what happened even when the output looks clean.
Quality metadata
Every response includes structured quality signals in the footer so Claude (or any orchestrator) can make informed trust decisions:
--- Model: qwen3-coder-30b-a3b | 413→81 tokens | TTFT: 2355ms, 15.0 tok/s, 5.4s | Quality: think-blocks-stripped, tokens-estimated 💰 Claude quota saved this session: 494 tokens across 1 offloaded call
Flags include: TRUNCATED (partial result), think-blocks-stripped, tokens-estimated (usage data was missing, estimated from content length), hit-max-tokens. When no flags fire, the quality line is omitted — clean output, nothing to report.
Session metrics resource
The houtini://metrics/session MCP resource exposes cumulative offload stats as JSON. Claude can read this proactively to make smarter delegation decisions based on actual session performance:
json{ "session": { "totalCalls": 14, "promptTokens": 3200, "completionTokens": 5250, "totalTokensOffloaded": 8450 }, "perModel": { "qwen3-coder-30b-a3b": { "calls": 14, "avgTtftMs": 2100, "avgTokPerSec": 15.2 } } }
Request serialisation
On local providers (LM Studio, Ollama, vLLM, llama.cpp) parallel MCP tool calls are automatically queued and run one at a time. A single-GPU host can only serve one request at a time anyway — without the semaphore, parallel calls stack timeouts and waste the generation budget.
On remote providers (OpenRouter, DeepSeek, Groq, Cerebras, and anything detected as a non-local backend) the semaphore is skipped — the upstream handles parallelism natively and serialising artificially would throttle you. This is automatic; you don't need to configure it.
Configuration
| Variable | Default | What it does |
|---|---|---|
HOUTINI_LM_ENDPOINT_URL | http://localhost:1234 | Base URL of the OpenAI-compatible API. Legacy alias: LM_STUDIO_URL. |
HOUTINI_LM_API_KEY | (none) | Bearer token for authenticated endpoints. Legacy aliases: LM_STUDIO_PASSWORD, LM_PASSWORD, OPENROUTER_API_KEY. |
HOUTINI_LM_MODEL | (auto-detect) | Model identifier — leave blank to use whatever's loaded. Legacy alias: LM_STUDIO_MODEL. |
HOUTINI_LM_PROVIDER | (auto-detect) | Force provider-specific handling. Set to openrouter for OpenRouter attribution headers, reasoning.exclude, and no inference serialisation. Otherwise auto-detected from the endpoint URL. |
HOUTINI_LM_CONTEXT_WINDOW | 100000 | Fallback context window if the API doesn't report it. Legacy alias: LM_CONTEXT_WINDOW. |
Compatible endpoints
Works with anything that speaks the OpenAI /v1/chat/completions API:
| What | URL | Notes |
|---|---|---|
| LM Studio | http://localhost:1234 | Default, zero config. Rich metadata via v0 API. |
| Ollama | http://localhost:11434 | Set HOUTINI_LM_ENDPOINT_URL. Thinking models (qwen3, deepseek-r1) handled transparently — reasoning is captured from Ollama's delta.reasoning channel and the output budget is inflated automatically so small thinking models don't return empty bodies. |
| OpenRouter | https://openrouter.ai/api | 300+ models from one endpoint. Auto-detected — sends attribution headers, uses reasoning.exclude for thinking models, retries 429/5xx with jittered backoff, parallel requests allowed. |
| vLLM | http://localhost:8000 | Native OpenAI API |
| llama.cpp | http://localhost:8080 | Server mode |
| DeepSeek | https://api.deepseek.com | 28c/M input tokens |
| Groq | https://api.groq.com/openai | ~750 tok/s |
| Cerebras | https://api.cerebras.ai | ~3000 tok/s |
| Any OpenAI-compatible API | Any URL | Set URL + password |
Streaming and timeouts
All inference uses Server-Sent Events streaming. Tokens arrive incrementally. Since v2.9.0, houtini-lm sends MCP progress notifications on every streamed chunk — including during the thinking phase for reasoning models — which resets the SDK's 60-second client timeout. A 5-minute soft timeout acts as a safety net so a genuinely wedged connection can't hold a tool call open indefinitely; as long as tokens keep flowing, the per-chunk progress keeps the client side alive up to that ceiling.
If the connection stalls (no new tokens for an extended period), you get a partial result instead of a timeout error. The footer shows TRUNCATED when this happens, and the quality metadata flags it so Claude knows to treat the output with appropriate caution.
Architecture
index.ts Main MCP server - tools, streaming, session tracking model-cache.ts SQLite-backed model profile cache (sql.js / WASM) Auto-profiles models via HuggingFace API at startup Persists to ~/.houtini-lm/model-cache.db Inference: POST /v1/chat/completions (OpenAI-compatible, works everywhere) Model metadata: GET /api/v0/models (LM Studio, falls back to /v1/models) Embeddings: POST /v1/embeddings (OpenAI-compatible)
Development
bashgit clone https://github.com/houtini-ai/lm.git cd lm npm install npm run build npm run shakedown # end-to-end self-test + benchmark
See DEVELOPER.md for architecture, internals, the reasoning-model pipeline, backend detection, the SQLite performance cache, and instructions for adding new tools or backends.
Licence
Apache-2.0