Connect and use Qwen3 Coder 480B A35B Instruct (FP8) from Chutes with API Key

How to use Qwen3 Coder 480B A35B Instruct (FP8) from Chutes with API Key
Learn how to access and use Qwen3 Coder 480B A35B Instruct (FP8) with your Chutes API key through TypingMind. Get started with this powerful AI model in minutes.
Chutes.ai is a decentralized serverless AI compute platform built on Bittensor Subnet 64, enabling developers to deploy, run, and scale AI models without managing infrastructure. The platform processes nearly 160 billion tokens daily serving over 400,000 users with up to 90% lower costs than traditional providers through a distributed network of GPU miners compensated with TAO tokens. Key features include always-hot serverless compute with instant inference, model-agnostic support for LLMs, image, and audio models plus custom code, fully abstracted infrastructure handling provisioning and scaling automatically, standardized API access with OpenRouter integration, and open pay-per-use pricing. The roadmap includes long-running jobs, fine-tuning capabilities, AI agents, and Trusted Execution Environments for enhanced privacy, with a startup accelerator offering up to $20,000 in credits.
Official Documentation: https://llm.chutes.ai/v1/models
Qwen3 Coder 480B A35B Instruct (FP8) Overview
| Model Name | Qwen3 Coder 480B A35B Instruct (FP8) |
| Provider | Chutes |
| Model ID | Qwen/Qwen3-Coder-480B-A35B-Instruct-FP8 |
| Release Date | Aug 1, 2025 |
| Last Updated | Aug 1, 2025 |
| Context Window | 262,144 tokens |
| Max Output | 262,144 tokens |
| Pricing /1M tokens | $0.2 input $0.8 output |
| Input Modalities | text |
| Output Modalities | text |
| Capabilities | Tool CallingTemperature Control |
Complete Setup Guide
Get Your Chutes API Key
First, you'll need to obtain an API key from Chutes. This key allows you to access their AI models directly and pay only for what you use.
- Visit Chutes's API console
- Sign up or log in to your account
- Navigate to the API keys section
- Generate a new API key (copy it immediately as some providers only show it once)
- Save your API key in a secure password manager or encrypted note
⚠️ Important: Keep your API key secure and never share it publicly. Store it safely as you'll need it to connect with TypingMind.
Configure TypingMind with Chutes API Key
- Open TypingMind in your browser
- Click the "Settings" icon (gear symbol)
- Navigate to "Models" section
- Click "Add Custom Model"
- Fill in the model information:Name:
Qwen/Qwen3-Coder-480B-A35B-Instruct-FP8 via Chutes(or your preferred name)Endpoint:https://llm.chutes.ai/v1/chat/completionsModel ID:Qwen/Qwen3-Coder-480B-A35B-Instruct-FP8Context Length: Enter the model's context window (e.g., 262144 for Qwen/Qwen3-Coder-480B-A35B-Instruct-FP8)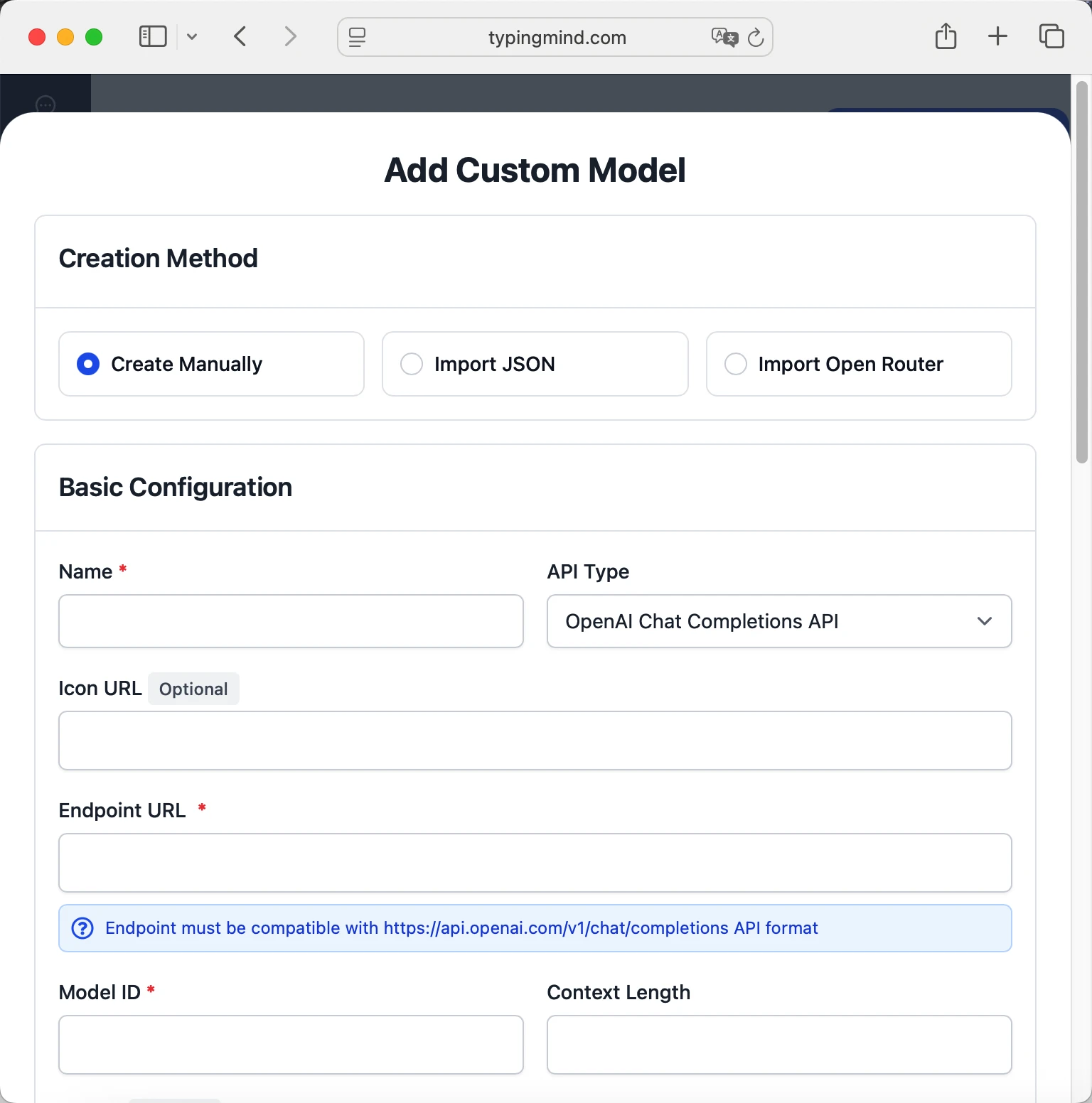 Qwen/Qwen3-Coder-480B-A35B-Instruct-FP8https://llm.chutes.ai/v1/chat/completionsQwen/Qwen3-Coder-480B-A35B-Instruct-FP8 via Chuteshttps://www.typingmind.com/model-logo.webp262144
Qwen/Qwen3-Coder-480B-A35B-Instruct-FP8https://llm.chutes.ai/v1/chat/completionsQwen/Qwen3-Coder-480B-A35B-Instruct-FP8 via Chuteshttps://www.typingmind.com/model-logo.webp262144 - Add custom headers by clicking "Add Custom Headers" in the Advanced Settings section:Authorization:
Bearer <CHUTES_API_KEY>:X-Title:typingmind.comHTTP-Referer:https://www.typingmind.com - Enable "Support Plugins (via OpenAI Functions)" if the model supports the "functions" or "tool_calls" parameter, or enable "Support OpenAI Vision" if the model supports vision.
- Click "Test" to verify the configuration
- If you see "Nice, the endpoint is working!", click "Add Model"
Start chatting with Qwen3 Coder 480B A35B Instruct (FP8)
Now you can start chatting with Qwen3 Coder 480B A35B Instruct (FP8) through TypingMind:
- Select Qwen3 Coder 480B A35B Instruct (FP8) from the model dropdown menu
- Start typing your message in the chat input
- Enjoy faster responses and better features than the official interface
- Switch between different AI models as needed
💡 Pro tips for better results:
- Use specific, detailed prompts for better responses (How to use Prompt Library)
- Create AI agents with custom instructions for repeated tasks (How to create AI Agents)
- Use plugins to extend Qwen3 Coder 480B A35B Instruct (FP8) capabilities (How to use plugins)
Frequently Asked Questions
Do I need a subscription to use Qwen3 Coder 480B A35B Instruct (FP8)?
No! With Chutes API, you pay only for what you use with no monthly subscription. Add credits to your Chutes account and pay as you go. TypingMind is also a one-time purchase, not a subscription.
How much will it cost to use Qwen3 Coder 480B A35B Instruct (FP8)?
Qwen3 Coder 480B A35B Instruct (FP8) costs $0.2/1M input tokens and $0.8/1M output tokens. A typical conversation might cost $0.01-0.10 depending on length.
Can I use other models besides Qwen3 Coder 480B A35B Instruct (FP8)?
Yes! With Chutes API + TypingMind, you can access all Chutes models. Switch between them instantly in TypingMind.
Is my data private and secure?
Yes! TypingMind stores conversations locally (web version in browser, desktop version on your device). Chutes handles API calls securely. Check Chutes's data policy for specifics.
Can I use Qwen3 Coder 480B A35B Instruct (FP8) for commercial projects?
Yes! Check Chutes's terms of service for specific commercial use policies. TypingMind supports commercial use.
 Kimi Dev 72B
Kimi Dev 72BConnect and use Kimi Dev 72B from chutes with API Key
Kimi Dev 72B from Chutes - Context: 131072 tokens
 Kimi K2 Instruct
Kimi K2 InstructConnect and use Kimi K2 Instruct from chutes with API Key
Kimi K2 Instruct from Chutes - Context: 75000 tokens
 Kimi K2 Instruct 0905
Kimi K2 Instruct 0905Connect and use Kimi K2 Instruct 0905 from chutes with API Key
Kimi K2 Instruct 0905 from Chutes - Context: 262144 tokens
 Kimi VL A3B Thinking
Kimi VL A3B ThinkingConnect and use Kimi VL A3B Thinking from chutes with API Key
Kimi VL A3B Thinking from Chutes - Context: 131072 tokens
 LongCat Flash Chat FP8
LongCat Flash Chat FP8Connect and use LongCat Flash Chat FP8 from chutes with API Key
LongCat Flash Chat FP8 from Chutes - Context: 131072 tokens
 DeepSeek R1T Chimera
DeepSeek R1T ChimeraConnect and use DeepSeek R1T Chimera from chutes with API Key
DeepSeek R1T Chimera from Chutes - Context: 163840 tokens
 DeepSeek TNG R1T2 Chimera
DeepSeek TNG R1T2 ChimeraConnect and use DeepSeek TNG R1T2 Chimera from chutes with API Key
DeepSeek TNG R1T2 Chimera from Chutes - Context: 163840 tokens
GPT OSS 120BConnect and use GPT OSS 120B from chutes with API Key
GPT OSS 120B from Chutes - Context: 131072 tokens
Devstral Small (2505)Connect and use Devstral Small (2505) from chutes with API Key
Devstral Small (2505) from Chutes - Context: 32768 tokens
 Mistral Small 3.2 24B Instruct (2506)
Mistral Small 3.2 24B Instruct (2506)Connect and use Mistral Small 3.2 24B Instruct (2506) from chutes with API Key
Mistral Small 3.2 24B Instruct (2506) from Chutes - Context: 131072 tokens
Qwen3 30B A3BConnect and use Qwen3 30B A3B from chutes with API Key
Qwen3 30B A3B from Chutes - Context: 40960 tokens
Qwen3 30B A3B Thinking 2507Connect and use Qwen3 30B A3B Thinking 2507 from chutes with API Key
Qwen3 30B A3B Thinking 2507 from Chutes - Context: 262144 tokens
