Access and Use Google: Gemini 2.5 Flash Lite Preview 06-17 via OpenRouter using API Key

Access and Use gemini-2.5-flash-lite-preview-06-17 via OpenRouter
Gemini 2.5 Flash-Lite is a lightweight reasoning model in the Gemini 2.5 family, optimized for ultra-low latency and cost efficiency. It offers improved throughput, faster token generation, and better performance across common benchmarks compared to earlier Flash models. By default, "thinking" (i.e. multi-pass reasoning) is disabled to prioritize speed, but developers can enable it via the Reasoning API parameter to selectively trade off cost for intelligence.
Google: Gemini 2.5 Flash Lite Preview 06-17 Overview
| Full Name | Google: Gemini 2.5 Flash Lite Preview 06-17 |
| Provider | |
| Model ID | google/gemini-2.5-flash-lite-preview-06-17 |
| Release Date | Jun 17, 2025 |
| Context Window | 1,048,576 tokens |
| Pricing /1M tokens | $0.0000001 for input $0.0000004 for output |
| Supported Input Types | file, image, text, audio |
| Supported Parameters | include_reasoningmax_tokensreasoningresponse_formatseedstopstructured_outputstemperaturetool_choicetoolstop_p |
Complete Setup Guide
Create OpenRouter Account
- Visit openrouter.ai
- Click "Sign In" and create an account (free)
- Verify your email address
- You'll receive $1 in free credits to test models
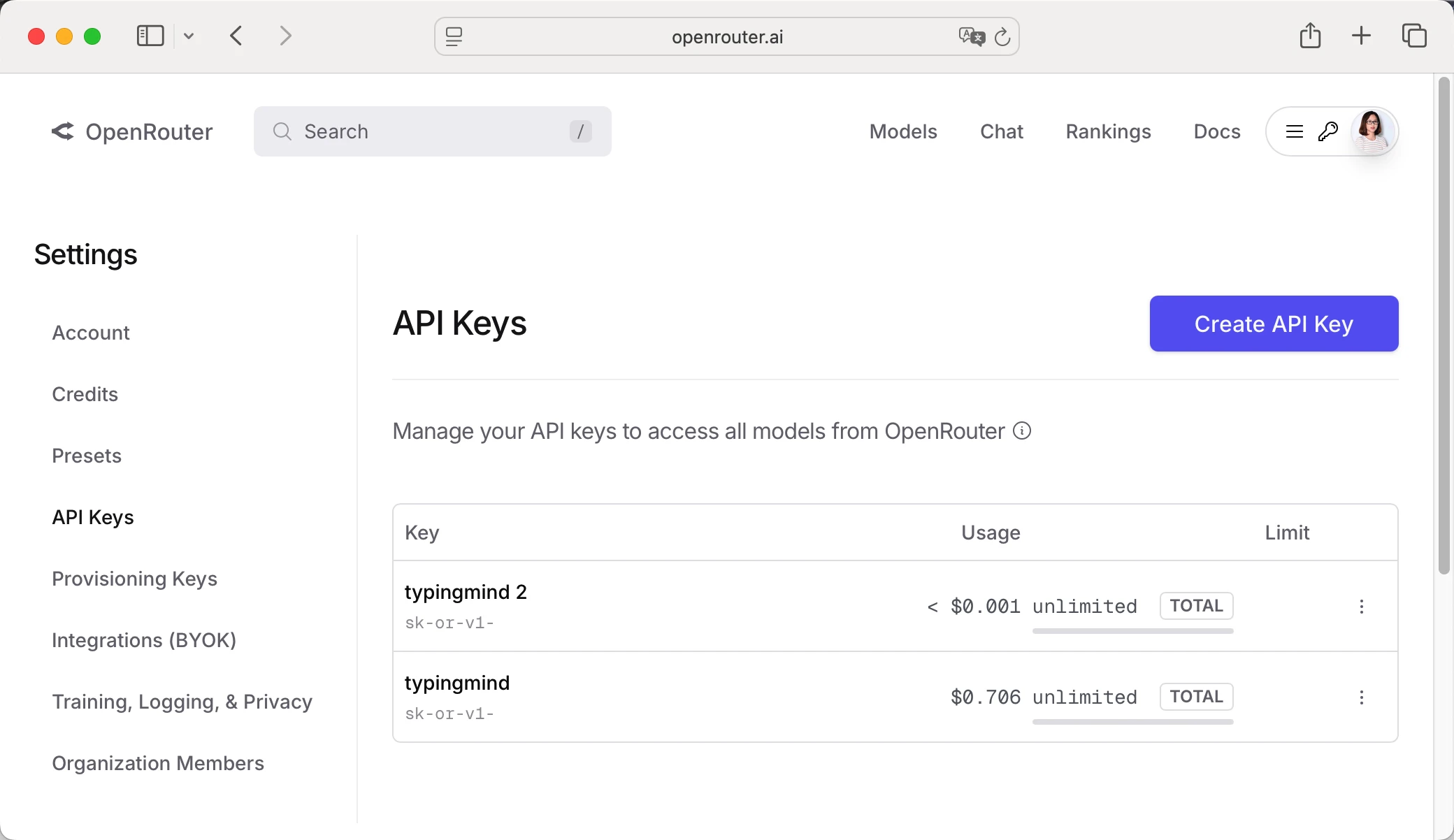
Get Your OpenRouter API Key
- Log in to OpenRouter dashboard
- Go to "API Keys" section in the menu
- Click "Create API Key"
- Give it a name (e.g., "TypingMind")
- Copy your API key (starts with "sk-or-v1-...")
Add Credits to OpenRouter (Optional)
- Go to "Credits" in OpenRouter dashboard
- Click "Add Credits"
- Choose amount ($5 minimum, $20 recommended for testing)
- Complete payment (credit card or crypto)
- Credits never expire!
Configure TypingMind with OpenRouter API Key
Method 1: Direct Import (Recommended)
- Open TypingMind in your browser
- Click the "Settings" icon (gear symbol)
- Navigate to "Manage Models" section
- Click "Add Custom Model"
- Select "Import OpenRouter" from the options
- Enter your OpenRouter API key from Step 1
- Click "Check API Key" to verify the connection
- Choose which models you want to add from the list (you can add multiple at once)
- Click "Import Models" to complete the setup
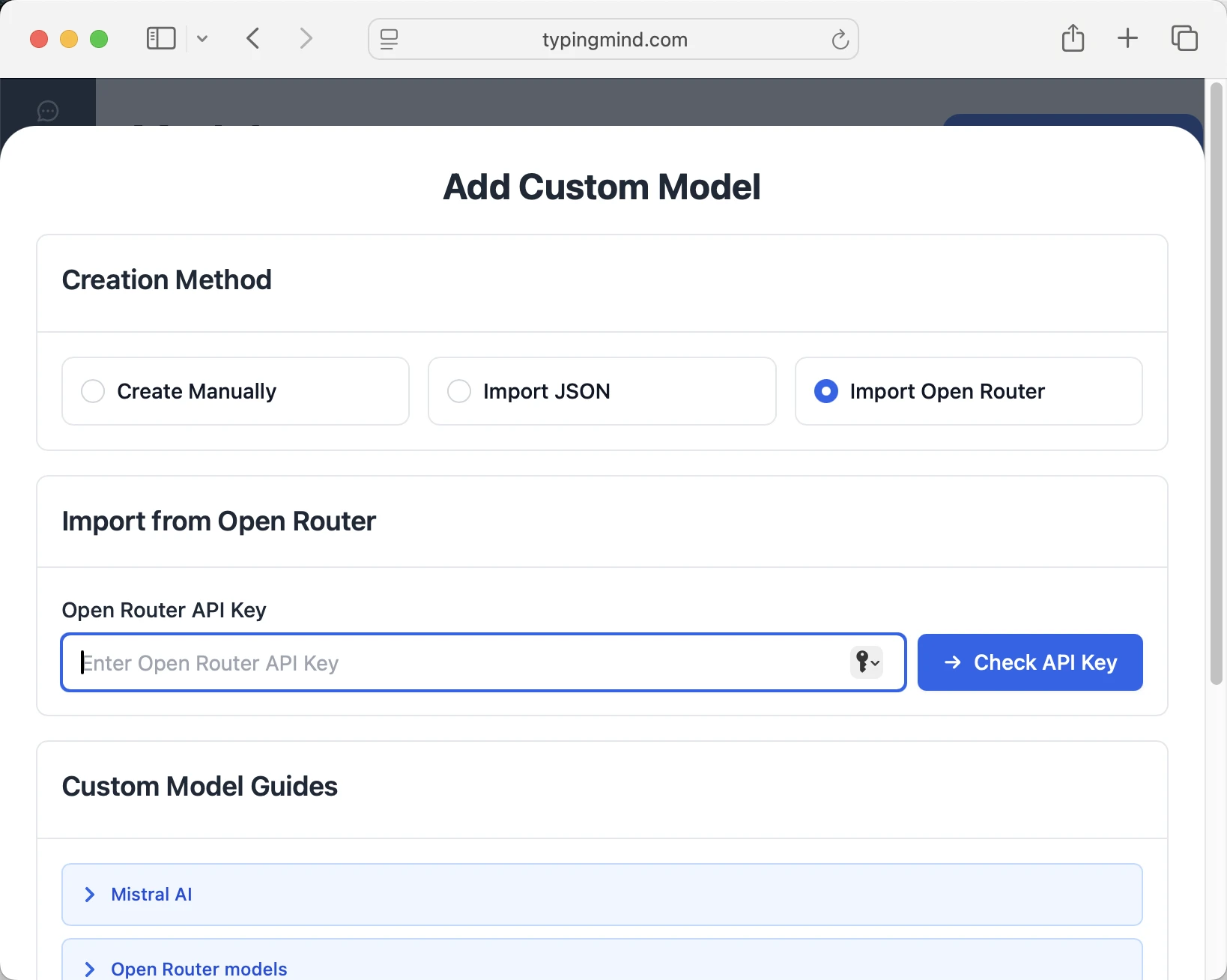
Method 2: Manual Custom Model Setup
- Open TypingMind in your browser
- Click the "Settings" icon (gear symbol)
- Navigate to "Models" section
- Click "Add Custom Model"
- Fill in the model information:Name:
google/gemini-2.5-flash-lite-preview-06-17 via OpenRouter(or your preferred name)Endpoint:https://openrouter.ai/api/v1/chat/completionsModel ID:google/gemini-2.5-flash-lite-preview-06-17Context Length: Enter the model's context window (e.g., 1048576 for google/gemini-2.5-flash-lite-preview-06-17)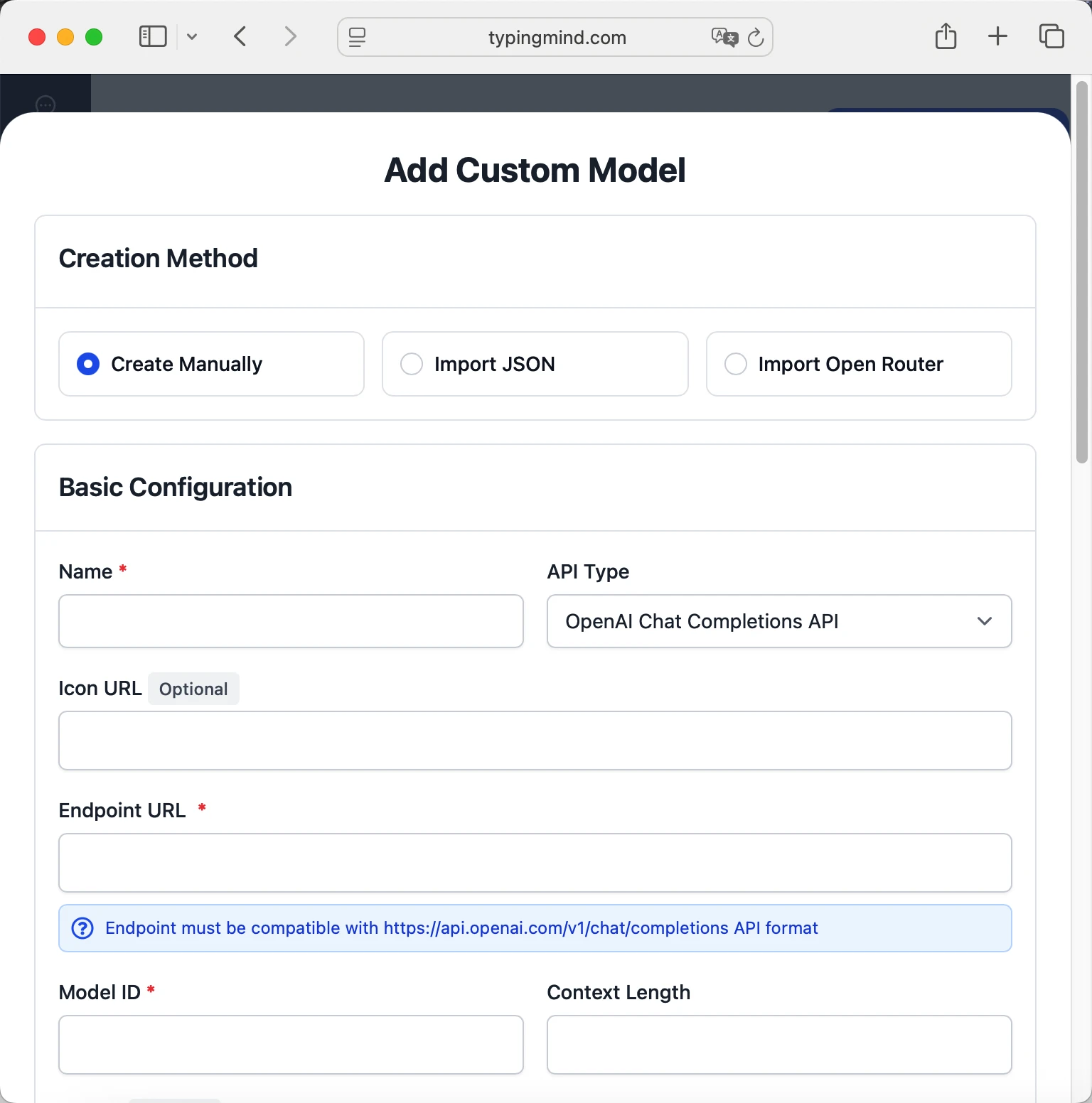 google/gemini-2.5-flash-lite-preview-06-17https://openrouter.ai/api/v1/chat/completionsgoogle/gemini-2.5-flash-lite-preview-06-17 via OpenRouterhttps://www.typingmind.com/model-logo.webp1048576
google/gemini-2.5-flash-lite-preview-06-17https://openrouter.ai/api/v1/chat/completionsgoogle/gemini-2.5-flash-lite-preview-06-17 via OpenRouterhttps://www.typingmind.com/model-logo.webp1048576 - Add custom headers by clicking "Add Custom Headers" in the Advanced Settings section:Authorization:
Bearer <OPENROUTER_API_KEY>:X-Title:typingmind.comHTTP-Referer:https://www.typingmind.com - Enable "Support Plugins (via OpenAI Functions)" if the model supports the "functions" or "tool_calls" parameter, or enable "Support OpenAI Vision" if the model supports vision.
- Click "Test" to verify the configuration
- If you see "Nice, the endpoint is working!", click "Add Model"
Start chatting with google/gemini-2.5-flash-lite-preview-06-17
Now you can start chatting with the google/gemini-2.5-flash-lite-preview-06-17 model via OpenRouter on TypingMind:
- Select your preferred google/gemini-2.5-flash-lite-preview-06-17 model from the model dropdown menu
- Start typing your message in the chat input
- Enjoy faster responses and better features than the official interface
- Switch between different AI models as needed
Pro tips for better results:
- Use specific, detailed prompts for better responses (How to use Prompt Library)
- Create AI agents with custom instructions for repeated tasks (How to create AI Agents)
- Use plugins to extend google/gemini-2.5-flash-lite-preview-06-17 capabilities (How to use plugins)
- Upload documents and images directly to chat for AI analysis and discussion (Chat with documents)
Why TypingMind + OpenRouter?
- Best-in-class UI: TypingMind's interface is far superior to standard chat UIs
- Model flexibility: Switch between Google: Gemini 2.5 Flash Lite Preview 06-17 and 200+ models instantly
- Cost control: Pay only for what you use through OpenRouter
- One-time purchase: Buy TypingMind once, use forever with any OpenRouter model
- Data privacy: Your conversations stored locally, not on external servers
Frequently Asked Questions
Do I need a subscription to use Google: Gemini 2.5 Flash Lite Preview 06-17?
No! Through OpenRouter, you pay only for what you use with no monthly subscription. Add credits to your OpenRouter account and they never expire. TypingMind is also a one-time purchase, not a subscription.
How much will it cost to use Google: Gemini 2.5 Flash Lite Preview 06-17?
It costs 0.0000001 for input and 0.0000004 for output via OpenRouter. A typical conversation might cost $0.01-0.10 depending on length. Start with $5-10 in credits to test.
Can I use other models besides Google: Gemini 2.5 Flash Lite Preview 06-17?
Yes! With OpenRouter + TypingMind, you get access to 200+ models including GPT-4, Claude, Gemini, Llama, Mistral, and many more. Switch between them instantly in TypingMind.
Is my data private and secure?
Yes! TypingMind stores conversations locally (web version in browser, desktop version on your device). OpenRouter handles API calls securely and doesn't train on your data. Check each provider's data policy for specifics.
Can I use Google: Gemini 2.5 Flash Lite Preview 06-17 for commercial projects?
Yes! Check Google's terms of service for specific commercial use policies. OpenRouter and TypingMind both support commercial use.
What if Google: Gemini 2.5 Flash Lite Preview 06-17 is unavailable?
OpenRouter allows you to configure fallback models. If Google: Gemini 2.5 Flash Lite Preview 06-17 is down, it can automatically route to your backup choice. You can also manually switch models in TypingMind anytime.
How do I cancel or get a refund?
OpenRouter: No subscriptions to cancel. Unused credits remain in your account forever.

Access Shisa AI: Shisa V2 Llama 3.3 70B via OpenRouter
Shisa V2 Llama 3.3 70B is a bilingual Japanese-English chat model fine-tuned by Shisa.AI on Meta’s Llama-3.3-70B-Instruct base. It prioritizes Japanese language performance while retaining strong English capabilities. The model was optimized entirely through post-training, using a refined mix of supervised fine-tuning (SFT) and DPO datasets including regenerated ShareGPT-style data, translation tasks, roleplaying conversations, and instruction-following prompts. Unlike earlier Shisa releases, this version avoids tokenizer modifications or extended pretraining. Shisa V2 70B achieves leading Japanese task performance across a wide range of custom and public benchmarks, including JA MT Bench, ELYZA 100, and Rakuda. It supports a 128K token context length and integrates smoothly with inference frameworks like vLLM and SGLang. While it inherits safety characteristics from its base model, no additional alignment was applied. The model is intended for high-performance bilingual chat, instruction following, and translation tasks across JA/EN.

Access OpenAI: GPT-4.1 via OpenRouter
GPT-4.1 is a flagship large language model optimized for advanced instruction following, real-world software engineering, and long-context reasoning. It supports a 1 million token context window and outperforms GPT-4o and GPT-4.5 across coding (54.6% SWE-bench Verified), instruction compliance (87.4% IFEval), and multimodal understanding benchmarks. It is tuned for precise code diffs, agent reliability, and high recall in large document contexts, making it ideal for agents, IDE tooling, and enterprise knowledge retrieval.

Access OpenAI: GPT-4.1 Mini via OpenRouter
GPT-4.1 Mini is a mid-sized model delivering performance competitive with GPT-4o at substantially lower latency and cost. It retains a 1 million token context window and scores 45.1% on hard instruction evals, 35.8% on MultiChallenge, and 84.1% on IFEval. Mini also shows strong coding ability (e.g., 31.6% on Aider’s polyglot diff benchmark) and vision understanding, making it suitable for interactive applications with tight performance constraints.

Access OpenAI: GPT-4.1 Nano via OpenRouter
For tasks that demand low latency, GPT‑4.1 nano is the fastest and cheapest model in the GPT-4.1 series. It delivers exceptional performance at a small size with its 1 million token context window, and scores 80.1% on MMLU, 50.3% on GPQA, and 9.8% on Aider polyglot coding – even higher than GPT‑4o mini. It’s ideal for tasks like classification or autocompletion.

Access EleutherAI: Llemma 7b via OpenRouter
Llemma 7B is a language model for mathematics. It was initialized with Code Llama 7B weights, and trained on the Proof-Pile-2 for 200B tokens. Llemma models are particularly strong at chain-of-thought mathematical reasoning and using computational tools for mathematics, such as Python and formal theorem provers.

Access AlfredPros: CodeLLaMa 7B Instruct Solidity via OpenRouter
A finetuned 7 billion parameters Code LLaMA - Instruct model to generate Solidity smart contract using 4-bit QLoRA finetuning provided by PEFT library.

Access ArliAI: QwQ 32B RpR v1 (free) via OpenRouter
QwQ-32B-ArliAI-RpR-v1 is a 32B parameter model fine-tuned from Qwen/QwQ-32B using a curated creative writing and roleplay dataset originally developed for the RPMax series. It is designed to maintain coherence and reasoning across long multi-turn conversations by introducing explicit reasoning steps per dialogue turn, generated and refined using the base model itself. The model was trained using RS-QLORA+ on 8K sequence lengths and supports up to 128K context windows (with practical performance around 32K). It is optimized for creative roleplay and dialogue generation, with an emphasis on minimizing cross-context repetition while preserving stylistic diversity.

Access ArliAI: QwQ 32B RpR v1 via OpenRouter
QwQ-32B-ArliAI-RpR-v1 is a 32B parameter model fine-tuned from Qwen/QwQ-32B using a curated creative writing and roleplay dataset originally developed for the RPMax series. It is designed to maintain coherence and reasoning across long multi-turn conversations by introducing explicit reasoning steps per dialogue turn, generated and refined using the base model itself. The model was trained using RS-QLORA+ on 8K sequence lengths and supports up to 128K context windows (with practical performance around 32K). It is optimized for creative roleplay and dialogue generation, with an emphasis on minimizing cross-context repetition while preserving stylistic diversity.

Access Agentica: Deepcoder 14B Preview (free) via OpenRouter
DeepCoder-14B-Preview is a 14B parameter code generation model fine-tuned from DeepSeek-R1-Distill-Qwen-14B using reinforcement learning with GRPO+ and iterative context lengthening. It is optimized for long-context program synthesis and achieves strong performance across coding benchmarks, including 60.6% on LiveCodeBench v5, competitive with models like o3-Mini

Access Agentica: Deepcoder 14B Preview via OpenRouter
DeepCoder-14B-Preview is a 14B parameter code generation model fine-tuned from DeepSeek-R1-Distill-Qwen-14B using reinforcement learning with GRPO+ and iterative context lengthening. It is optimized for long-context program synthesis and achieves strong performance across coding benchmarks, including 60.6% on LiveCodeBench v5, competitive with models like o3-Mini

Access MoonshotAI: Kimi VL A3B Thinking (free) via OpenRouter
Kimi-VL is a lightweight Mixture-of-Experts vision-language model that activates only 2.8B parameters per step while delivering strong performance on multimodal reasoning and long-context tasks. The Kimi-VL-A3B-Thinking variant, fine-tuned with chain-of-thought and reinforcement learning, excels in math and visual reasoning benchmarks like MathVision, MMMU, and MathVista, rivaling much larger models such as Qwen2.5-VL-7B and Gemma-3-12B. It supports 128K context and high-resolution input via its MoonViT encoder.

Access MoonshotAI: Kimi VL A3B Thinking via OpenRouter
Kimi-VL is a lightweight Mixture-of-Experts vision-language model that activates only 2.8B parameters per step while delivering strong performance on multimodal reasoning and long-context tasks. The Kimi-VL-A3B-Thinking variant, fine-tuned with chain-of-thought and reinforcement learning, excels in math and visual reasoning benchmarks like MathVision, MMMU, and MathVista, rivaling much larger models such as Qwen2.5-VL-7B and Gemma-3-12B. It supports 128K context and high-resolution input via its MoonViT encoder.
